






Benefits and Costs of Regulation
It is usual for regulators to evaluate the cost-benefit of the regulatory suggestions.... Read More

The term “big data” refers to structured or unstructured data that is significant, fast, or complex, thus strenuous or even impossible to process using traditional methods. The incorporation of big data has prompt implications for building a machine learning model and financial forecasting.
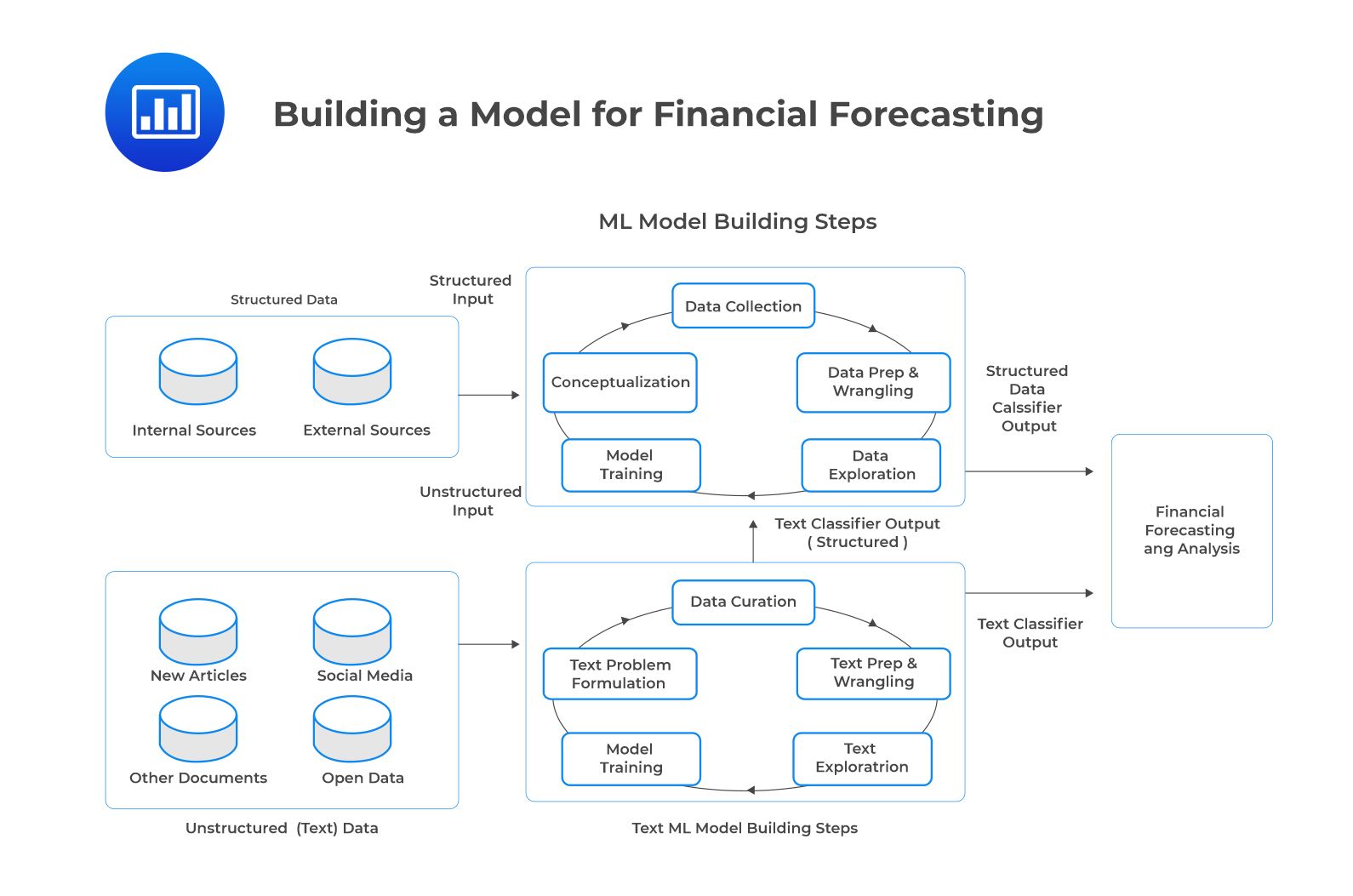
The steps for building a machine learning model using structured (traditional) big data are as follows:
Step 1: Conceptualization of the modeling task.
This step requires establishing the model output, how and who will use the model, and how the output will be planted in existing or new business.
Step 2: Data collection.
Structured data can be obtained from both internal and external sources.
Step 3: Data preparation and wrangling.
Cleansing and preprocessing of raw data takes place in this step. Cleansing involves resolving missing values or outliers, whereas preprocessing entails extracting, accumulating, filtering, and selecting relevant data columns.
Step 4: Data exploration.
The data exploration step involves exploratory data analysis, selecting, and engineering features.
Step 5: Model training.
The suitable machine learning approach is selected in this step. Moreover, the performance of the trained model is evaluated, and the model is tuned accordingly.
These steps are repetitive since model building is an iterative process.
Building text ML models requires different steps since they incorporate unstructured data sources of big data. The differences in steps between the text model and traditional model account for the characteristics of big data: volume, velocity, variety, and veracity. Here, we focus on the variety and veracity attributes of big data as they are apparent in the text.
Text ML model building steps are as follows:
Step 1: Text problem formulation.
This step entails the formulate text classification problem and identifying the exact inputs and outputs for the model. Further, it is crucial to establish how the text ML model’s classification output will be put to use.
Step 2: Text curation.
Relevant text data is obtained from web pages through scraping or crawling programs.
Step 3: Text preparation and wrangling.
This step entails cleansing and preprocessing tasks required for converting unstructured data into a format that is usable by traditional modeling methods designed for structured inputs.
Step 4: Text exploration.
Here, text is visualized through methods such as word clouds. Additionally, it involves text feature selection and engineering
Finally, the output can either be combined with other structured variables or used directly for forecasting and analysis.
The following figure demonstrates the above steps of building a model for financial forecasting using structured (traditional) vs. unstructured (text) big data.
 Question
QuestionConsider the following statements:
Statement 1: “The second step in building text-based machine learning models is text preparation and wrangling. However, the second step in building machine learning models using structured data is data collection.”
Statement 2: “The fourth step in building both types of models encompasses data/text exploration.”
Which of the statements relating to the steps in building structured data-based and text-based machine learning models is (are) accurate?
A. Only Statement 1.
B. Only Statement 2.
C. Both Statement 1 and Statement 2.
Solution
The correct answer is B.
The five steps in building structured data-based machine learning models are:
- Conceptualization of the modeling task
- Data collection
- Data preparation and wrangling
- Data exploration
- Model training.
The five steps in building text-based ML models are:
- Text problem formulation
- Data (text) curation
- Text preparation and wrangling
- Text exploration
- Model training.
Statement 2 is correct since the fourth step in building both types of models involves data/text exploration.
A and C are incorrect. Text preparation and wrangling is the third step in building text ML models and occurs after the second data (text) curation step.
Reading 7: Big Data Projects
LOS 7 (a) Identify and explain steps in a data analysis project
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.