






Interest Rate Forward and Futures Cont ...
The most used interest rate in the derivatives market is the LIBOR which... Read More

Data preparation and wrangling is a crucial step that entails cleaning and organizing raw data in a consolidated format that allows for more convenient consumption of the data. Data collection precedes the data preparation and wrangling stage. Recall that before data collection begins, it is essential to state the problem, define the objectives, identify useful data points, and conceptualize the model. What follows is collecting the relevant data through exploring and downloading raw data from different sources.
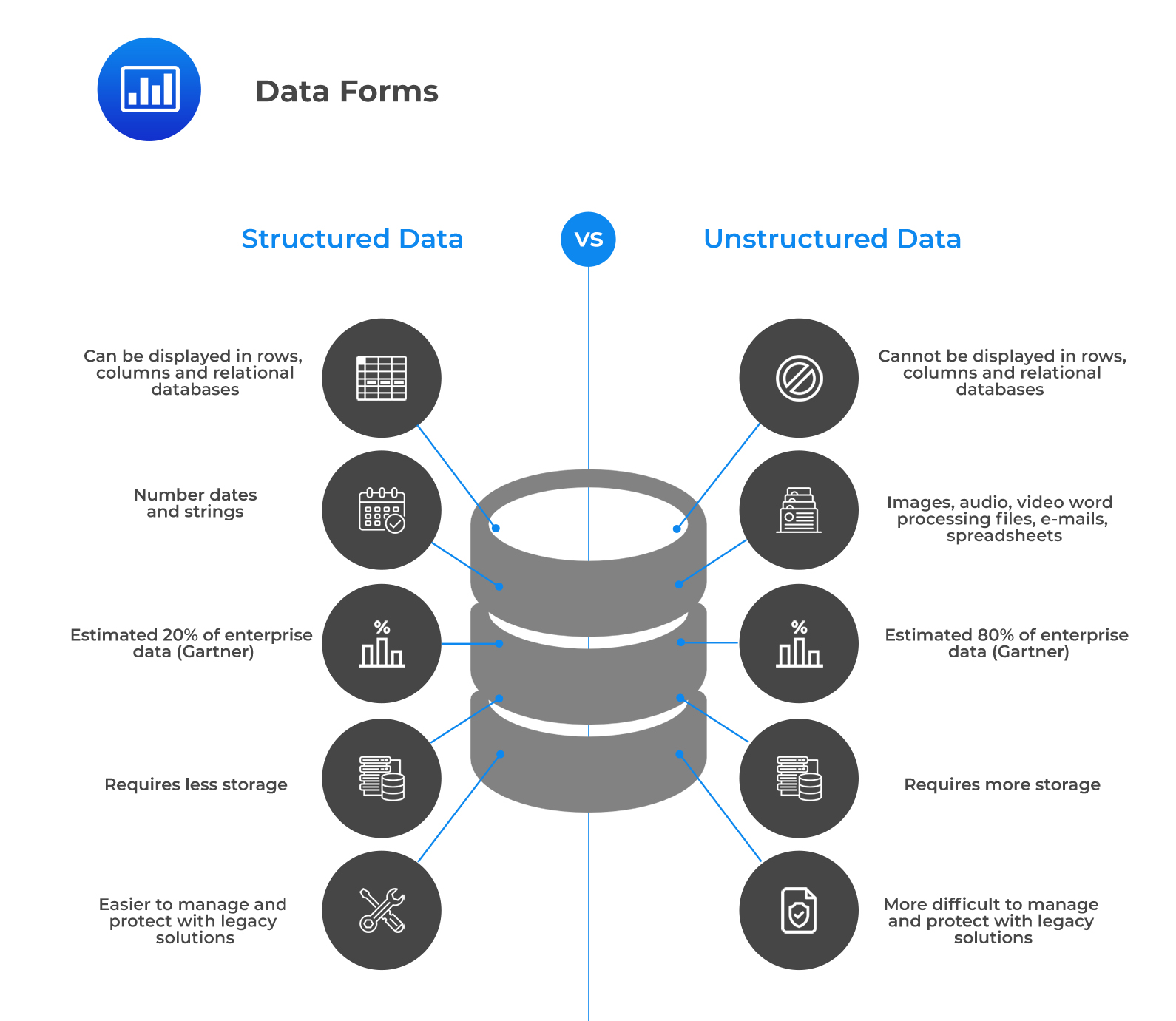
Preliminary to delving into data preparation and wrangling, it is vital to differentiate the two forms of data that can be collected, i.e., structured and unstructured data. The figure below gives the different features of the two data forms.
 The data preparation and wrangling stage involves two crucial tasks: cleansing and preprocessing, respectively.
The data preparation and wrangling stage involves two crucial tasks: cleansing and preprocessing, respectively.
Data Preparation (Cleansing): This refers to the process of inspecting, pinpointing, and reducing errors in raw data. Raw data can be invalid, inaccurate, incomplete, or have duplicates either due to mistakes during manual data entry or server failures or system bugs for data recorded by the system.
Data Wrangling (Preprocessing): After data is cleaned, it needs to be processed by managing the outliers, extracting handy variables from the existing data points, and scaling the features of the data. This prepares the data for model consumption.
To establish possible errors associated with structured data, we look at the following sample of raw data obtained from a credit company.
$$\small{\begin{array}{l|l|l|l|l|l|l|l} 1 & \textbf{ID} & \textbf{Name} & \textbf{Gender} & \textbf{Salary (\$)} & \textbf{Loan Amount (\$)} & \textbf{Loan Outcome} & \textbf{Loan Type}\\ \hline 2 & 1 & \text{Ms. Phi} & \text{F} & 120,000 & 48,000 & \text{No default} & \text{Car}\\ \hline 3 & 2 & \text{Mr. Psi} & \text{M} & 100,000 & \text{Unknown} & \text{No default} & \text{Student loan}\\ \hline 4 & 3 & \text{Ms. Tau} & \text{F} & (40,000) & 16,000 & \text{No default} & \text{Mortgage}\\ \hline 5 & 4 & \text{Mr. Epsilon} & \text{F} & 90,000 & 36,000 & \text{Defaulted} & \text{Car}\\ \hline 6 & 5 & \text{Mr. Rho} & \text{M} & 83,000 & 33,200 & \text{No default} & {}\\ \hline 7 & 6 & \text{Mr. Rho} & \text{M} & 83,000 & 33,200 & \text{No default} & \text{Mortgage}\\ \hline 8 & 7 & \text{Ms. Chi} & \text{F} & 95,000 & 38,000 & \text{No default} & \text{Mortgage}\\ \end{array}}$$
1. Incompleteness error: This is missing data due to the absence of some data entries. The data shown for Mr. Rho shows an incompleteness error because the loan type is missing. Missing values should be omitted or replaced with NA. The NA can then be substituted with options such as mean, median, or mode, or 0.
2. Invalidity error: Arises when some data values are out of a meaningful range. The data shown for Mrs. Tau contains invalidity error since salary cannot be negative. Invalid entries should be verified with other data records.
3. Inaccuracy error: Occurs when the data is not a measure of actual value. The data for Mr. Psi indicates an unknown loan amount, yet the loan outcome shows that he did not default. The lender must know how much he lends this particular borrower.
4. Inconsistency error: This is as a result of some of the data conflicting with the corresponding data points or reality. The data for Mr. Epsilon is likely to be inconsistent as the Name column contains a male title, but the Gender column contains a female. Clarifying the data with another source solves this error.
5. Non-uniformity error: Emerges where the data are ambiguous or non-identical data formats. For example, the monetary unit for the salary and loan amount is $. This ambiguous because the dollar symbol can represent the US dollar, Canadian dollar, or others. Converting the data points into a preferable standard format can resolve this error.
6. Duplication error: This is as a result of the repetition of identical data points. The data shown for Mr. Rho contains duplication error. This error can be resolved by removing the duplicates.
What follows after data cleaning is data preprocessing, which involves transforming and scaling data. These transformations may include:
1. Extraction: This entails extracting a new variable from the current variable to simplify the analysis and use it for the ML model training.
2. Aggregation: Two or more variables can be combined to form one variable to consolidate similar variables.
3. Filtration: Data rows not necessary for the analysis must be pinpointed and filtered.
4. Selection: The data columns that are intuitively not required for the analysis can be eliminated. For example, the Name column, in this case, is not required for training the ML model.
5. Conversion: The different variable types in the dataset must be converted into appropriate types to process further and analyze them correctly. For example, Name and Loan Type are nominal, Salary and Loan Amount are continuous, and Gender and Loan Outcome are categorical with 2 classes.
The next step is to identify outliers present the data. For normally distributed data, a data value outside of 3 standard deviations from the mean may be considered an outlier. An interquartile range (IQR) can also be used to identify outliers. Data values outside 1.5 IQR are considered outliers, while those outside 3IQR are extreme values.
Trimming/Truncation refers to removing extreme values and outliers from the data set. For example, a 10% trimmed dataset is one for which the 10% highest and the 10% lowest values have been eliminated. On the other hand, winsorization refers to replacing extreme values and outliers with the maximum and the minimum values of data points that are not outliers.
Feature scaling entails making sure that features are on a similar scale, shifting, and changing the scale of data. Scaling follows after eliminating the outliers.
1. Normalization is the process of adjusting one or more attributes to the range of 0 to 1. It is sensitive to outliers and can be used when the distribution of the data is unknown. To normalize a random variable X:
Example 1:
$$X_{i(normalized)}=\frac{X_{i}-X_{Min}}{X_{Max}-X_{Min}}$$
2. Standardization typically means adjusting data to have a mean of 0 and a standard deviation of 1 (i.e., unit variance). It is reasonably less sensitive to outliers as it depends on the mean and standard deviation of the data. Standardization applies to data that has a normal distribution.
Equation 2:
$$X_{i(Standardized)}=\frac{X_{i}-\mu}{\sigma}$$
Where:
The objective of data preparation and wrangling of textual data is to transform the unstructured data into structured data. The output of these processes is a document term matrix that can be read by computers. The document term matrix is similar to a data table for structured data. The cleansing and preprocessing of unstructured text data into a structured format is called text processing. Preparing unstructured data is more challenging relative to structured data. We will use text data related to the English language to demonstrate this section.
This step involves removing unnecessary HTML tags, punctuation, and white spaces from the raw text. The cleansing process is as follows:
Step1: Remove HTML tags.
HTML tags that are not part of the actual text can be removed using a programming language or a regular expression (regex).
Step 2: Remove punctuations.
Some punctuations, such as percentage signs and question marks, may be useful for ML model training. Therefore, when such punctuation is removed, annotations such as /percentSign/ and /questionMark/ should be added to maintain their grammatical meaning in the text. Regex is commonly applied to remove or replace punctuations.
Step 3: Remove numbers.
Numbers present in the text should be removed or replaced by annotations such as /number/. This is critical because the computers treat each number as a separate word, complicating the analyses or adding noise.
Step 4: Remove white spaces.
Extra spaces such as tabs, line breaks, and new lines should be identified and removed to keep the text intact and clean. The stripWhitespace function in R can be utilized to can be used to eliminate unnecessary white spaces from the text.
We begin this section by defining token and tokenization to understand text processing further. A token corresponds to a word, while tokenization is the process of breaking down a given text into separate tokens. For example, “This is good” has 3 tokens, i.e., “This,” “is,” and “good.”
Text data also require normalization, just like structured data. The normalization process in text processing entails the following:
Step 1: Lowercasing the alphabet aids the computer to process identical words appropriately.
Step 2: Stop words such as “the,” “for,” and “are,” usually are removed to reduce the number of tokens involved in the training set for ML training purposes.
Step 3: Stemming is the process of converting words from their base forms or stems using crude Heuristic rules. For example, the stem of the words “increased” and “increasing” is “increas.” Stemming solves the problem that emerges when some words appear very infrequently in a textual dataset posing the risk of training highly complex models.
Step 4: Lemmatization is identical to stemming except that it removes endings only if the base form is present in a dictionary. Lemmatization is much more costly and advanced relative to stemming.
What follows after text normalization is creating a bag-of-words (BOW). A BOW is a representation for analyzing text. It does not, however, represent the word sequences or positions.
Suppose we have a series of sentences:
“This is good.”
“This is valuable.”
“This is fine.”
The following figure is a Bag-of-Words representation of the three sentences before and after the normalization process.
 The final Bow after normalizing is then used to build a document term matrix (DTM). It is a matrix where each row belongs to a text file, and each column represents a token. The number of rows is equivalent to the number of text files in a sample text dataset. The number of columns is equal to the number of tokens from the BOW built using all the text files in the same token is present in each document.
The final Bow after normalizing is then used to build a document term matrix (DTM). It is a matrix where each row belongs to a text file, and each column represents a token. The number of rows is equivalent to the number of text files in a sample text dataset. The number of columns is equal to the number of tokens from the BOW built using all the text files in the same token is present in each document.
The following figure shows a DTM constructed from the resultant BOW of the three sentences.
$$\small{\begin{array}{l|l|l|l} {}&\textbf{Good}&\textbf{Valu}&\textbf{Fine}\\ \hline\text{Sentence 1}&1&0&0\\ \hline\text{Sentence 2}&0&1&0\\ \hline\text{Sentence 3}& 0&0&1\\ \end{array}}$$
As mentioned earlier, a BOW does not represent the word sequences or positions, which limits its use for some advanced ML training applications. For example, if a text has the word “no.” It can be treated as a single token and treated as a stop word during normalization. This would fail to imply negative meaning.
N-gram is a technique used to overcome such a problem as it is a representation of word sequences. A two-word sequence is a bigram, a three-word sequence is a trigram, etc.
Question
A data scientist of a large investment corporation is discussing with her senior manager about the steps involved in preprocessing raw text data. She tells her senior manager that the process can be accomplished in the following three steps:
Step 1: Cleanse the raw text data.
Step 2: Split the cleansed data into a collection of words for them to be normalized.
Step 3: Normalize the collection of words and create a well-defined set of tokens from the normalized words.
The data scientist’s step 2 is most likely to be:
A. Lemmatization.
B. Standardization.
C. Tokenization.
Solution
The correct answer is C.
Tokenization refers to the process of dividing a given text into separate tokens. This step takes place after cleansing the raw text data, i.e., removing HTML tags, numbers, and extra white spaces. The tokens are then normalized to create the bag-of-words (BOW).
A is incorrect. Lemmatization is a text normalization technique of reducing inflected words while ensuring that the root word belongs to the language. In Lemmatization, root word is called Lemma. A lemma is the dictionary form or citation form of a set of words. For example, the lemma of the words “analyzed” and “analyzing” is “analyze.”
B is incorrect. Standardization is a scaling technique that entails adjusting data to have a mean \((\mu)\) of 0 and a standard deviation \((\sigma)\) of 1 (i.e., unit variance).
Reading 7: Big Data Projects
LOS 7 (b) Describe objectives, steps, and examples of preparing and wrangling data
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.