






Artificial Intelligence and Machine Le ...
After completing this reading, you should be able to: Describe the drivers contributing... Read More

After completing this reading, you should be able to:
Machine learning is a branch of artificial intelligence (AI) that uses algorithms to identify patterns in a data set and then make decisions, just like humans. It aims to imitate how humans learn, gradually improving its predictive power and accuracy. Machine learning is premised on the realization that machines can learn without being programmed to perform specific tasks. Machine learning algorithms use statistical methods to uncover key insights within a data set and then make relevant classifications or predictions.
In recent years, machine learning has gained a strong foothold in the financial industry, particularly banking and insurance. It has been used to decide the amount of money to lend to customers, provide warning signals to traders, detect fraud, and improve compliance with rules and regulations. This chapter explores ways machine learning and AI can improve risk management by leveraging the large volume of data available. We also look at the core machine learning techniques which can be applied to improve risk management.
Machine learning falls into two broad categories: supervised and unsupervised machine learning.
Supervised learning is a machine learning technique where models are trained using labeled data. The goal is to find the mapping function that maps the input variable (X) with the output variable (Y).
$$ Y = f(x) $$
The word “supervised” comes from the fact that the algorithms used aren’t left to deduce the relationship between X and Y on their own. Instead, the machine is trained using data that are already labeled. It’s pretty much like providing the machine with some questions that are already tagged with the correct answers and then asking it to find the answers to untagged but similar questions.
Regression machine learning is a technique that predicts a single output (dependent variable) value using training data (independent variables). For example, we can use regression to model the risk of loan repayment using a range of explanatory variables, including average nonpayment rates, employment status, credit history, and other outstanding liabilities.
One advantage of machine learning regression over traditional regression is that we can include a larger number of independent variables that can be discarded automatically if they lack any explanatory power. For example, LASSO regression eliminates variables with zero regression power. In contrast, Ridge regression gives lower weights to variables that are highly correlated with other variables in a model. We can also begin with zero power for all variables and gradually add the variables found to have explanatory power.
Supervised learning employs a technique known as Principal Component Analysis (PCA) to simplify complex datasets. PCA is a statistical procedure that transforms potentially correlated variables into a smaller number of uncorrelated variables called principal components. The objective of PCA is to reduce the dimensionality of the data while retaining as much information as possible.
Consider a scenario where you’re modeling credit repayment risk as the dependent variable. Among the independent variables, you have (I) owns a house, (II) owns a car, and (III) has bank savings. Each of these variables represents different aspects of a person’s financial status and can potentially influence their credit repayment risk.
In a real-world dataset, there might be many such variables, making the analysis complex and computationally intensive. This is where PCA comes in. Rather than working with all these variables independently, PCA identifies the commonalities among these variables and combines them into a smaller set of synthesized variables – the ‘principal components.’
In our example, PCA could combine the three original variables into a single variable – asset ownership. This new variable captures the shared variance among the original variables, thereby encapsulating the underlying construct of ‘financial stability’ that they collectively represent. By doing so, PCA enables a more efficient and manageable analysis without sacrificing too much valuable information.
It’s important to note, however, that the results of PCA must be interpreted cautiously. The original meaning of the variables can get lost or distorted in the PCA process, and the principal components might not always have a clear or intuitive meaning.
Classification involves grouping data into labeled classes. For example, when modeling the likelihood of default, we could have two categories: Potential defaulters and non-defaulters. The model would then be trained on how to classify the data into one of the two classes in an accurate manner. In binary classification, the model works with just two labels – 0 and 1 (yes and no). In the case of multi-class classification, the model classifies data into more than one class.
In unsupervised learning, models are not supervised or trained using labeled data. Instead, models find hidden patterns and insights from the given data without human intervention. The goal is to identify previously undetected patterns and discover the internal structure of a data set without predefined output categories. Unsupervised learning methods are used to perform more complex processing tasks compared to supervised learning. For example, a bank could create an algorithm to scrutinize customer accounts and identify those with similarities. This could help the bank develop a product that specifically targets those account holders.
Clustering mainly deals with finding a natural structure or pattern in a collection of raw, unclassified data. Unsupervised learning clustering algorithms scour the data to identify any notable clusters (groups).
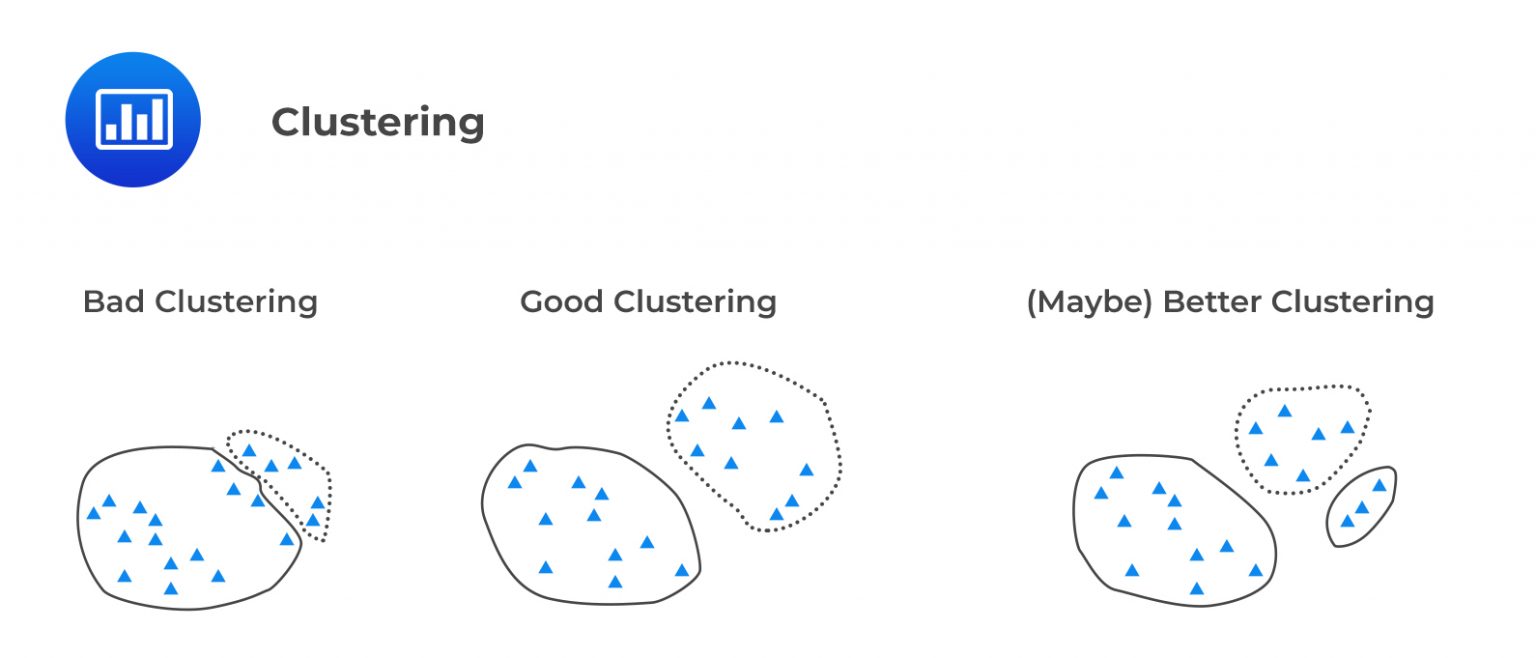
One area where clustering is applied is the detection of spam emails. If an email looks like others deemed spam, it is also likely to be spam.
There are several clustering approaches, but the most popular one is k-means clustering. Under k-means clustering, the desired number of clusters, k, is predetermined. The algorithm is then tasked with clustering the data into the k groups through an iterative process. A larger k means you’ve got smaller groupings with more granularity, while a lower k means larger groupings with less granularity. Iteration is aimed at maximizing the difference in means between determined groups. Each group or cluster has its own centroid (central focal point). If we have two clusters, A and B, and a data point Y is closer to the centroid (mean) of A than B, then Y is put in cluster A.
Dimensionality reduction is used to analyze and obtain a better representation of data. The data set should have less redundant information at the end of the process, but the important parts may be emphasized. In practice, this technique is used to hive off a section of a large amount of data for closer scrutiny.
In addition to supervised and unsupervised machine learning techniques, we have deep learning and neural networks – other branches of machine learning that can be supervised, unsupervised, or semi-supervised. The two are used to model super complex relationships between variables and ultimately to better mimic human decision-making. A key feature of deep learning is that problems are modeled in a multi-layer network that is extremely difficult to comprehend. As the input data progresses through the model, it’s combined and recombined to form new factors with weights that depend on the combinations made in the previous layer. This leads to output that’s essentially been worked out in a “black box.” This perceived lack of transparency and clarity over decisions made by the model can complicate risk management and can be a source of risk for firms. This is an issue that has widely been mentioned in the digital lending market, where the software used essentially runs borrower data through a black box to determine whether they are eligible for loans and how much they should get.
For a long time, firms relied on classical linear, logit, and probit regressions to model credit risk. However, in recent years, there’s been a realization that AI and machine learning can significantly improve credit risk management and help firms make better lending decisions. Studies have shown that credit risk can be modeled more accurately by combining traditional statistical methods of distress and bankruptcy prediction and neural network algorithms.
One area where machine learning has proved extremely useful is the credit risk analysis of credit default swaps. This is because, in the CDS market, there are many uncertain elements involved in the determination of the likelihood of a default (credit) event and the estimation of the cost of default in case a default materializes. In a 14-year study conducted between 2001 and 2014 involving CDSs of different maturities and rating groups, nonparametric machine learning models outperformed traditional benchmark models regarding prediction accuracy. The nonparametric machine learning models also performed better in terms of suggesting the most practical hedging tools.
Banks are increasingly relying on machine learning to make better consumer and SME lending decisions.
Market risk emanates from exposure to the financial market, including investing and trading in various assets such as stocks and bonds. Machine learning has been used in several market risk management areas:
Operational risk concerns itself with risks emanating from both internal and external operational breakdowns. Such risks are attributable to people (e.g., strikes and go-slows), systems, frauds, neglected procedures, or natural disasters. In recent years, operational risks have become more complex and frequent, prompting firms to explore a path toward artificial intelligence and machine learning-based solutions.
AI and machine learning can help firms to:
AI and machine learning can be effective tools against fraud. This happens when firms automate routine tasks to minimize human error. Besides, machine learning and AI can be employed in processing unstructured data to screen out relevant content or negative news and evaluate the extent of interconnectedness among individuals to assess how prone they might be to an external attack. Further, AI tools can be used to monitor individual traders by combining trade data and their electronic and voice communications records. Lastly, AI tools can single out alerts that need a more urgent response.
Any firm that wants a sound risk management system must comply with all risk management regulations. To help with compliance, most firms have turned to RegTech – a subset of fintech that focuses on technologies that can facilitate the delivery of regulatory requirements more efficiently and effectively compared to the existing traditional capabilities. AI is an excellent RegTech tool because it allows for continuous monitoring of firm activities. This way, the firm has access to real-time insights that help it avoid compliance breaches rather than dealing with the consequences of breaches after they have occurred.
For risk management, AI and machines offer several key benefits:
Several practical issues plague the use of AI and machine learning techniques in risk management:
Question
In the context of the Credit Default Swap (CDS) market, a financial institution is contemplating the use of artificial intelligence (AI) and machine learning techniques to manage its credit risk. Which of the following statements is correct regarding the application of these techniques?
A. AI and machine learning techniques are best suited for evaluating and improving the liquidity of CDS instruments in the secondary market.
B. AI and machine learning techniques are primarily useful for enhancing customer interactions in the context of the CDS market.
C. The use of AI and machine learning in the CDS market is most valuable for improving audit trails and ensuring regulatory compliance.
D. Employing AI and machine learning techniques can improve the prediction accuracy of credit events and default costs in the CDS market.
Solution
The correct answer is D.
While AI and machine learning techniques can have a range of applications within financial markets, in the Credit Default Swap (CDS) market specifically, their primary value stems from their potential to handle the complexity and uncertainty of assessing credit risk. These technologies, particularly models involving deep learning, can enhance the prediction accuracy of credit events (i.e., the likelihood of a default) and the estimation of default costs. This predictive capability is vital for managing risk and making informed investment decisions in the CDS market.
Options A, B, and C, although plausible applications of AI and machine learning techniques, don’t directly address the key challenges inherent in credit risk assessment within the CDS market. Therefore, option D is the most likely correct answer.
Strengthen your FRM understanding of supervised and unsupervised learning, predictive models, fraud detection, and AI applications in financial risk management.
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.