






Valuation of Equities and Currencies u ...
Some underlying instruments have carry benefits. These benefits include dividends for stock options,... Read More

Machine learning employs the idea that systems can learn from data, identify patterns, and make decisions with minimal human intervention. It has an iterative aspect in that when models are exposed to new data, they can adapt independently.
Machine learning has several branches, which include; supervised learning, unsupervised learning, and deep learning, and reinforcement learning.
With supervised learning, the algorithm is given a set of particular targets to aim for. Supervised learning uses labeled data set, one that contains matched sets of observed inputs, X’s, and the associated outputs, Y’s. The algorithm is “trained,” i.e., the machine learning algorithm is applied to this data set to infer the patterns between the inputs and outputs. In other words, the algorithm works out \(f\) in the equation:
$$Y=f(X)$$
The dependent variable (Y) is the target, while the independent variables (X’s) are known as features.
Supervised learning can be categorized into two problems, depending on the nature of the target (Y) variable. These include classification and regression.
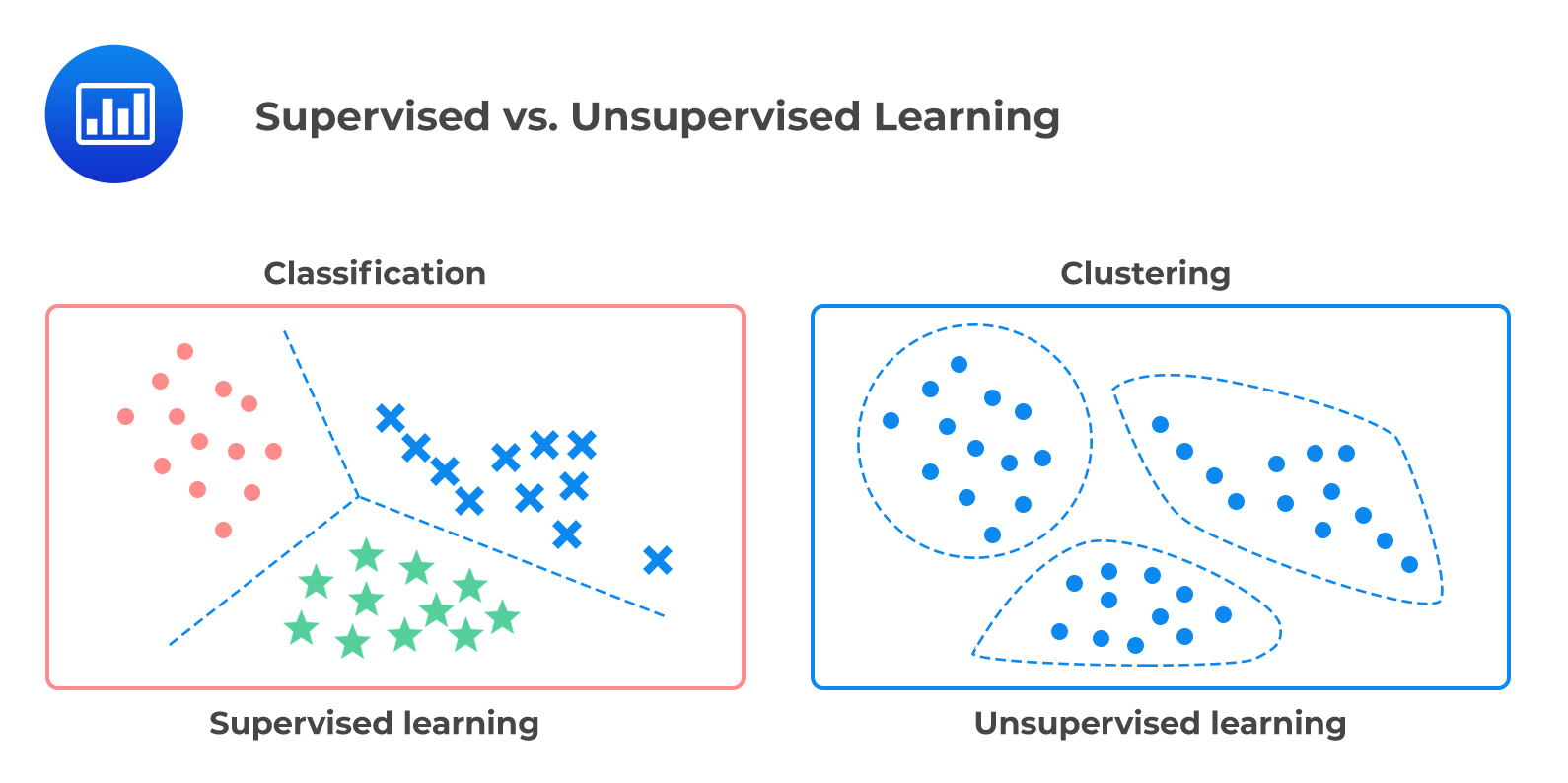
Classification focuses on sorting observations into distinct categories. It is when the target (Y) is a category, such as “blue” or “red” or “disease” and “no disease.” An example of a classification problem is a spam filter that classifies emails into two categories, ‘safe’ or ‘suspicious.’
Regression is based on making predictions of continuous target variables. Examples of regression problems include using historical stock market returns to forecast stock price performance or predicting the number of goals scored by a team.
The algorithm aims to produce a set of suitable labels (targets) under unsupervised learning. In other words, we have inputs (X’s) that are used for analysis with no corresponding target (Y). Unsupervised learning seeks to model the underlying structure or distribution in the data to learn more about the data since it is not given labeled training data. It is, therefore, useful for exploring new data sets that are large and complex.
Two essential types of unsupervised learning are dimension reduction and clustering.
Dimension reduction refers to reducing the number of inputs (features) while retaining variation across observations to maintain structure and usefulness of the information contained in the variation. For example, data scientists reduce the number of dimensions in an extensive data set to simplify modeling and reduce file size.
On the other hand, clustering seeks to sort observations into clusters (groups) such that the observations within a cluster are similar, while those in different clusters are dissimilar. For example, asset managers use clustering to sort companies into empirically determined groupings rather than conventional groupings, i.e., based on their financial statement data rather than sectors or countries.
The following displays the difference between supervised learning and unsupervised learning:
 Deep Learning and Reinforcement Learning
Deep Learning and Reinforcement LearningDeep learning and reinforcement learning functions enable a computer to develop rules on its own to solve problems.
Deep learning is a self-teaching system in which the existing data is used to train algorithms to establish patterns and then use that to make predictions about new data. Highly complex tasks, such as image classification, face recognition, speech recognition, and natural language processing, are addressed by sophisticated algorithms.
In reinforcement learning, a computer learns from trial and error. It learns dynamically by adjusting actions based on continuous feedback to maximize an outcome.
Deep learning and reinforcement learning are based on neural networks (NNs, also called artificial neural networks or ANNs). NNs include highly flexible ML algorithms that have been successfully applied to a variety of tasks characterized by nonlinearities and interactions among features.
The following chart summarizes the discussion on machine learning techniques:
Question
Which of the following statements most likely differentiates supervised learning from unsupervised learning?
Supervised learning involves:
A. Using labeled data to infer the patterns between the inputs and outputs.
B. Using unlabeled data to infer the patterns between the inputs and outputs.
C. Using existing data to train algorithms to establish patterns and then use that to make predictions about new data.
Solution
The correct answer is A.
Supervised learning uses a labeled data set to infer the patterns between the inputs and outputs.
B is incorrect. Option B describes unsupervised learning. With unsupervised learning, inputs (X’s) are used for analysis with no corresponding target (Y). Unsupervised learning seeks to model the underlying structure or distribution in the data to learn more about the data since it is not given labeled training data.
C is incorrect. Using existing data to train algorithms to establish patterns and then use those patterns to make predictions about new data best describes deep learning.
Reading 6: Machine Learning
LOS 6 (a) Describe supervised machine learning, unsupervised machine learning, and deep learning.
Practice supervised learning, unsupervised learning, deep learning, and machine learning applications in investment management with CFA Level II study notes, practice questions, video lessons, and mock exams.
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.