






Illiquid Assets
After completing this reading, you should be able to: Explain the essential features... Read More

After completing this reading, you should be able to:
Machine learning is a powerful tool mainly used for prediction purposes. It identifies relationships or patterns in a data sample, enabling it to create a model that incorporates those relationships that lead to the most potent out-of-sample predictions. The model is produced after running variables and the model on subsamples of the data to identify the most powerful predictors. The model is then tested on many different data subsamples. This can be repeated so that the model can “learn” from the data and improve its predictive performance.
Machine learning has a close association with the big data revolution since it relies on large datasets and massive computing power. The significant theoretical advances in machine learning and the remarkable speed-wise improvements in computing in recent years have led to a renaissance in computational modeling.
Some supervised machine learning approaches have the ability to perform non-parametric analyses due to their accuracy. These analyses can flexibly fit any model to estimate the data. Several machine learning approaches are also able to infer nonlinear relationships making them better fit the data.
The following figure demonstrates a typical machine learning process.
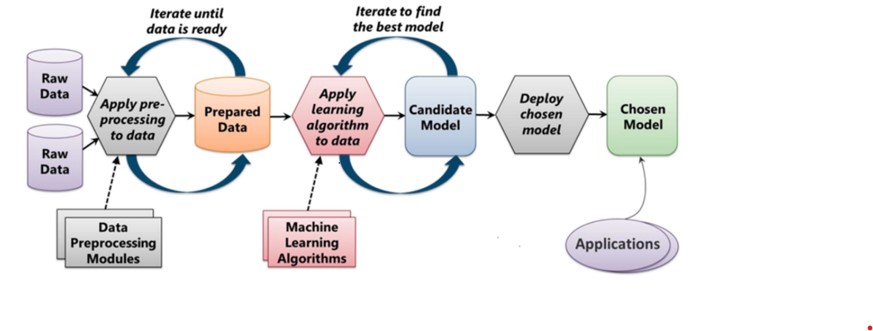
Machine learning consists of a broad range of analytical tools categorized as supervised and unsupervised learning tools. With supervised learning, the algorithm is given a set of particular targets to aim for. Supervised learning uses a labeled data set, one that contains matched sets of observed inputs, X’s, and the associated output, Y’s. On the other hand, the algorithm aims to produce a set of suitable labels (targets) under unsupervised learning. In other words, we have inputs (X’s) that are used for analysis with no corresponding target (Y). Unsupervised learning seeks to model the underlying structure or distribution in the data to learn more about the data since it is not given labeled training data. It is, therefore, useful for exploring new data sets that are large and complex.
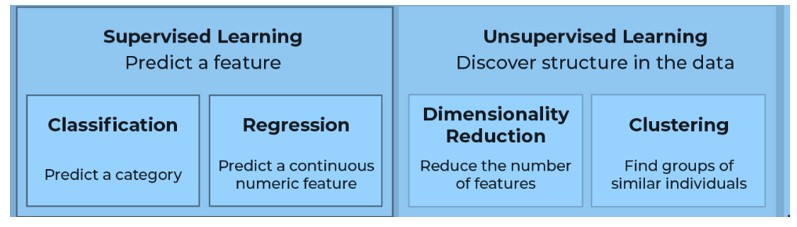
The machine learning spectrum contains several analytical methods. The applicability of the various machine learning approaches depends on the types of statistical problems to be addressed. Machine learning can be applied to regression, classification, and clustering classes of statistical problems.
Supervised learning can be categorized into two problems, depending on the nature of the target (Y) variable. These include classification and regression.
This involves the prediction of quantitative and continuous dependent variables, such as inflation. Linear learning methods such as principal component analysis and partial least squares can solve regression problems. Additionally, nonlinear learning methods that may be used to solve regression problems include neural networks, deep learning, and penalized regression approaches, such as elastic nets and LASSO. A factor is usually added to penalize the complexity of a model in penalized approaches for improving its predictive performance.
Note: Lasso, or least absolute shrinkage and selection operator, is a regression analysis method that performs both variable selection and regularization in order to enhance the prediction accuracy and interpretability of the statistical model it produces.
This involves the prediction of a qualitative, discrete dependent variable, which takes on values in a class. Filtering spam e-mail is a classification problem, where the dependent variable takes on the value’s ‘spam’ or ‘no spam.’ Nonlinear methods such as decision trees aim to deliver a structured set of YES or NO questions, quickly sorting through a comprehensive set of features, and hence producing an accurate prediction of a particular outcome.
Support vector machines (SVM) that employ both linear and nonlinear methods can also classify observations. Under SVM, classification is done by applying and optimizing a margin that separates the different classes more efficiently.
Recall that unlike supervised learning, unsupervised learning does not use labeled data. The algorithm finds patterns within the data. The two main categories of unsupervised ML algorithms are dimension reduction, using principal components analysis, and clustering, which includes k-means and hierarchical clustering. Here, we will only focus on the clustering problem.
In clustering, the input variables are observed, but the corresponding dependent variable is lacking. For example, banks are forced to explore data to detect fraud without obtaining feedback from authorities as to which observations are fraudulent and which not. An anti-money laundering (AML) analysis can yield insights from the data by creating cluster groupings according to their observed characteristics. This allows an analyst to understand similarities in transactions. Unsupervised learning may be applied to explore a dataset, and then the outputs obtained are used as inputs for supervised learning methods.
The following is a clear demonstration of the machine learning approaches:
Financial institutions have gathered large amounts of data, as details of reporting requirements have increased. The digitalization of services has also contributed to the creation of a large amount of high-frequency, unstructured consumer data. Therefore, these institutions require more powerful analytical tools that can cope with the massive amounts of data of different formats and from different sources. Additionally, there is a need to maintain and improve the details of the analysis.
After the 2008-2009 financial crisis, many new regulations and supervisory measures have been introduced, requiring financial institutions to give more detailed reports frequently, including more aspects of their business models and balance sheets. Therefore, banks report on significant exposures, liquidity measures, and capital levels. The Federal reserve’s comprehensive capital analysis and review (CCAR) exercise require financial institutions to consider the impact of multiple economic variables on their business. All these reporting data needs to be well structured, aggregated, and send to the supervisors.
A financial institution’s business model is regulated and supervised with detailed risk metrics. This scrutiny makes running a financial institution increasingly a matter of optimization with hundreds of constraints. Obtaining an optimum will give them a competitive advantage. Additionally, they also need to obtain consumer data for a more detailed insight into their preferences and behavior. The various machine learning approaches can cope with enormous datasets and details of the analysis.
Financial institutions have traditionally used linear, logit, and probit regression models to model credit risk for capital requirements and internal risk management procedures. Quite a several financial institutions have started experimenting with the application of machine learning methods to improve financial risk predictions. Unsupervised machine learning methods are used to explore the data. In contrast, regression and classification methods such as decision trees and support vector machines predict key credit risk variables as the probability of default or loss-given default. The banks provide their extensive records of loan-level data as inputs.
Machine learning is hard to apply due to the sophisticated methods and sensitivity of the models to overfitting the data. Therefore, the quality of the data found in banks is not always fit enough for advanced statistical analysis. More so, banks may not always consolidate the data obtained across the financial group. This consolidation may fail due to inconsistent definitions of data across jurisdictions and the use of different systems.
Non-parametric and nonlinear approaches that support vector machines, neural networks, and deep learning are complicated and almost impossible for any human to understand and audit from the outside. This makes the models barely useful for regulatory purposes. Financial supervisors require risk models to be clear, simple, understandable, and verifiable.
However, machine learning can be employed to optimize parameters and models with a regulatory function. This can be done by the application of linear and straightforward nonlinear machine learning approaches that can still perform better than similar non-machine learning approaches
Machine learning has been significantly successful in the detection of credit card fraud for more than a decade. Banks’ credit card payment infrastructure is equipped with monitoring systems referred to as workflow engines that monitor payments for potentially fraudulent activities. Fraudulent transactions can thus be blocked in real-time.
Fraud models employed by these engines have been trained on historical payment data. The availability of vast amounts of credit card transactions implies big datasets essential for algorithm training, backtesting, and validation. Moreover, banks can verify unambiguously the fraudulent or non-fraudulent transactions enabling them to obtain precise historical data to train classification algorithms.
Machine-learning systems, on the other hand, can potentially improve detecting money-laundering activities due to their ability to identify intricate patterns in data. They can also combine transaction information, at network speed, with data from various sources to obtain a holistic picture of a client’s activity and thus bringing the false positives down significantly.
However, money laundering is hard to define, as there does not exist a universally agreed definition of money laundering. Besides, financial institutions do not receive feedback from law enforcement agencies on which of their reported suspicious activities were money laundering. It is, therefore, difficult to train machine learning-detection algorithms using historical data.
This hurdle can be addressed by clustering. Recall that clustering is an unsupervised learning method. It can automatically find patterns in large datasets without the need for labels. It works by identifying outliers; that is, points without any strong membership in any of the cluster groups, which helps find anomalies within subsets of the data.
Machine learning is also applied in the surveillance of conduct breaches by traders working for the financial institutions. Such breaches include trading violations that can lead to high financial and reputational costs for the institutions. Machine learning can be used to do the following.
Machine learning approaches can identify large and complex patterns in data allowing for a generation of systems that can analyze entire trading portfolios. These systems can also link trading information to behavioral information of a trader, including e-mail traffic, building check-in and checkout-times, phone calls, among others. Technologies, such as natural language processing and text mining, have made those sources machine-readable and suitable for automated analysis. A ‘normal’ behavior profile is established. When a trader’s behavior or the trading performance differs from what is labeled as normal, the system sends an alert to the financial institutions’ compliance team.
Supervisory learning approaches are hard to apply: There is a lack of labeled data to train algorithms as financial institutions are not able to share with the developer’s sensitive information about past breaches legally.
The “black box” character of learning approaches: A surveillance system should be auditable for both supervisors and compliance officers. Therefore, it should be clear to a compliance officer as to why specific behavior has set off an alert. However, this may be difficult for systems based entirely on machine learning due to their “black box” character of learning approaches.
Incorporating human decisions and behavioral traits: A learning system should be found on a behavioral science-based model that incorporates human decisions and behavioral traits. This model can address the lack of explanatory power of the machine learning approaches. All alerts from the system are based on deviations identified from the model. Moreover, the incorporation of machine learning approaches with the model creates a feedback loop in the system that enables adaption to the evolving behavior, taking in more data to be as close as possible to understanding a trader’s patterns.
Practice Question
What characteristics do the ability of machine learning methods to analyze very large amounts of data exhibit in the context of predictive analysis?
A. A possibility of performing an extensive analysis and outputting a single value (e.g. “true” or “false”)
B. A data output which requires a significant amount of manual correction to be useful
C. It gives a general idea of the factors involved in predictive analysis
D. It allows for high granularity and depth of the predictive analysis being performed
The correct answer is: D).
The ability of machine learning methods to analyze very large amounts of data, while offering a high granularity and depth of predictive analysis, can significantly improve analytical capabilities across risk management and compliance areas, such as money laundering detection and credit risk modeling.
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.