






Credit Value Adjustment (CVA)
After completing this reading, you should be able to: Explain the motivation for... Read More
After completing this reading, you should be able to:
OpRisk taxonomy refers to the process of identifying and classifying operational risks.
To be able to build a robust risk management framework, a firm must successfully come up with a comprehensive risk classification structure. However, risk taxonomy in general is hardly an easy task, and firms usually make mistakes in the process. Risk classification mistakes made in the past years will have repercussions in risk management and on the communication of risks, at a minimum, to outside parties such as regulators. In fact, such mistakes might compromise any good work done elsewhere in the framework. There are roughly three ways through which firms drive this risk taxonomy exercise: cause-driven, impact-driven, and event-driven approaches.
The table below summarizes the seven level 1 categories of OpRisk according to the Basel committee. These categories can be broken down further into level 2 subcategories which help to further classify the type of loss event.
$$ \textbf{Table 1 – Level 1 Categories of Operational Risk Events} $$
$$ \begin{array}{l|l} \textbf{Event category} & \textbf{Definition} \\ \hline {\text{Execution, Delivery & Process}\\ \text{Management}} & {\text {Losses from failed transaction } \\ \text {processing or process management, from } \\ \text{relations with trade counterparties and} \\ \text{vendors.}} \\ \hline \text{Clients, products and business practices} & {\text{Losses arising from an unintentional or } \\ \text{negligent failure to meet a professional } \\ \text{obligation to specific clients (including} \\ \text{fiduciary and suitability requirements), } \\ \text{or from the nature or design of a } \\ \text{product.}} \\ \hline \text{Business disruption and system failures} & {\text{Losses arising from disruption of } \\ \text{business or system failures.}} \\ \hline \text{Damage to physical assets} & {\text{Losses arising from loss or damage to} \\ \text{physical assets from natural disaster or} \\ \text{other events.}} \\ \hline {\text{Employment practices and workspace} \\ \text{safety}} & {\text{Losses arising from acts inconsistent } \\ \text{with employment, health or safety laws } \\ \text{or agreements, from payment of personal} \\ \text{injury claims or from} \\ \text{diversity/discrimination events.} } \\ \hline \text{External fraud} & {\text{Losses due to acts of a type intended to } \\ \text{defraud, misappropriate property or } \\ \text{circumvent the law, by a third party.}} \\ \hline \text{Internal fraud} & {\text{Losses due to acts of a type intended to } \\ \text{defraud, misappropriate property or} \\ \text{circumvent regulations, the law or } \\ \text{company policy, excluding diversity/ } \\ \text{discrimination events, which involves at} \\ \text{least one internal party} } \end{array} $$
Let’s now look into each level 1 category in detail:
These losses emanate from failed transaction processing or process management, and from relations with trade counterparties and vendors. Losses of this event type are quite frequent since they can be due to human errors, miscommunications, and so on. These losses are very common in an environment where banks have to process millions of transactions per day.
EDPM is further split into 6 level 2 categories.
$$ \textbf{Table 2 – Level 2 Categories: EDPM} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline {\text{Execution, Delivery &} \\ \text{Process Management} } & { \text{Transaction Capture,} \\ \text{Execution and} \\ \text{Maintenance}} & {\text{Miscommunication; data } \\ \text{entry, missed deadline or } \\ \text{responsibility; accounting } \\ \text{error/entity attribution } \\ \text{error; delivery failure; }} \\ \hline {} & \text{Monitoring and Reporting} & { \text{Failed mandatory } \\ \text{reporting obligation;} \\ \text{inaccurate external report } \\ \text{(loss incurred)}} \\ \hline {} & {\text{Customer Intake and } \\ \text{Documentation} } & {\text{Client} \\ \text{permissions/disclaimers} \\ \text{missing legal documents} \\ \text{missing/incomplete} }\\ \hline {} & {\text{Customer/Client Account} \\ \text{Management} } & {\text{Unapproved access given } \\ \text{to accounts; incorrect} \\ \text{client records (loss} \\ \text{incurred); negligent loss } \\ \text{or damage of client assets} }\\ \hline {} & \text{Trade Counterparties} & {\text{Nonclient counterparty } \\ \text{misperformance; misc. } \\ \text{nonclient counterparty } \\ \text{disputes}} \\ \hline {} & \text{Vendors and Suppliers} & { \text{Outsourcing; vendor } \\ \text{disputes}} \end{array} $$
This category has one of the highest numbers of loss events, particularly in the US. It encompasses losses, for example, from disputes with clients and counterparties, regulatory fines from improper business practices, or wrongful advisory activities.
CPBP is further split into 5 level 2 categories.
$$ \textbf{Table 3 – Level 2 Categories: CPBP} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline {\text{Clients, products and } \\ \text{business practices} } & { \text{Suitability, Disclosure,} \\ \text{and Fiduciary} } & {\text{Fiduciary } \\ \text{breaches/guideline } \\ \text{violations; disclosure } \\ \text{issues (e.g., KYC); retail } \\ \text{customer disclosure} \\ \text{violations; breach of } \\ \text{privacy; misuse of} \\ \text{confidential information} } \\ \hline { } & { \text{Improper Business or } \\ \text{Market Practices} } & {\text{Antitrust; improper trade } \\ \text{practices; market } \\ \text{manipulation; insider } \\ \text{trading (on firm’s } \\ \text{account); unlicensed } \\ \text{activity; money } \\ \text{laundering} } \\ \hline { } & \text{Product Flaws} & {\text{Product defects (e.g., } \\ \text{unauthorised); model } \\ \text{errors}} \\ \hline { } & { \text{Selection, Sponsorship, } \\ \text{and Exposure} } & {\text{Failure to investigate } \\ \text{client per guidelines; } \\ \text{exceeding client exposure } \\ \text{limits} } \\ \hline { } & \text{Advisory Activities} & {\text{Disputes over } \\ \text{performance of advisory } \\ \text{activities} } \end{array} $$
Events under the BDSF category can be quite difficult to spot. For example, a system crash almost always comes with financial costs. However, these losses would most likely be classified as EDPM. To see how this might come about, consider the derivative department of a large bank that happens to experience a crash at 9:00 am. The IT department tries to do all it can, including turning to backup plans, all in vain. The system comes back online at 5:00 pm when money markets are already closed. On checking the transaction status, the bank learns that it needs to fund an extra USD 10 billion on that day. Since the markets are already closed, the bank is forced to negotiate for special conditions with its counterparties; but the rates at which the transactions are settled ultimately end up being higher than the daily average. Although this extra cost has actually come up due to a BDSF event – a system failure – it will most likely be categorized as part of EDPM, or fail to be captured at all.
$$ \textbf{Table 4 – Level 2 Categories: BDSF} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline {\text{Business Disruption and } \\ \text{System Failures} } & \text{Systems} & {\text{Hardware; software; } \\ \text{telecommunications; } \\ \text{utility outage/disruptions} } \\ \end{array} $$
The other risk event refers to damage to physical assets. This can result from natural disaster losses; or human losses from external sources (e.g., terrorism and vandalism). Only a few firms actively suffer losses from this risk type. This is because such losses are usually either too small or incredibly large.
$$ \textbf{Table 5 – Level 2 categories: DPA} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline {\text{Damage to Physical } \\ \text{Assets} } & \text{Disasters and other events} & {\text{Natural disaster losses; } \\ \text{human losses from } \\ \text{external sources (e.g., } \\ \text{terrorism, vandalism)} } \\ \end{array} $$
EPWS has three subcategories: (1) employee relations, (2) safe environment, and (3) diversity and discrimination. It is more prominent in parts of the world where either labor laws are old-fashioned and/or there is a culture of litigation against employers. This is, especially, the case in the Americas.
$$ \textbf{Table 6 – Level 2 categories: EPWS} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline {\text{Employment Practices and } \\ \text{Workplace Safety} } & \text{Employee relations} & {\text{Compensation, benefit, } \\ \text{termination issues; } \\ \text{organized labor activity} } \\ \hline {} & \text{Safe environment} & { \text{General liability (e.g., slip} \\ \text{and fall.); employee health } \\ \text{and safety rules events; } \\ \text{workers compensation} } \\ \hline {} & {\text{Diversity and } \\ \text{discrimination} } & \text{All discrimination types } \\ \end{array} $$
External fraud includes all forms of fraud perpetrated by third parties or outsiders against a firm. In banking, good examples would be system hacking and cheque and credit card fraud. In recent years, external fraud has cost financial firms millions of dollars.
$$ \textbf{Table 7 – Level 2 categories: EF} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline \text{External Fraud} & \text{Theft and fraud} & {\text{Theft/robbery; forgery; } \\ \text{check kiting }} \\ \hline {} & \text{Systems security} & { \text{Hacking damage; theft of } \\ \text{information (w/monetary } \\ \text{loss)} } \\ \end{array} $$
Internal fraud includes any fraudulent activity perpetrated by a firm’s employees. It is one of the less frequent types of opRisk loss mainly because institutions have over the years invested in sophisticated internal controls. However, cases of internal fraud still occur, and billions of dollars are still lost.
Internal fraud is characterized by low-frequency/high-severity events.
$$ \textbf{Table 8 – Level 2 categories: IF} $$
$$ \begin{array}{l|l|l} \textbf{Level 1 Category} & \textbf{Level 2 categories} & \textbf{Examples} \\ \hline \text{External Fraud} & \text{Theft and fraud} & {\text{Transactions not reported } \\ \text{(intentional); transaction type } \\ \text{unauthorized (w/monetary loss); } \\ \text{mismarking of position } \\ \text{(intentional)} } \\ \hline {} & \text{Theft and fraud} & { \text{Fraud/credit fraud/worthless } \\ \text{deposits; theft/ } \\ \text{extortion/embezzlement/robbery; } \\ \text{misappropriation of assets, } \\ \text{malicious destruction of assets; } \\ \text{forgery; check kiting; } \\ \text{smuggling; account take-} \\ \text{over/impersonation/ etc.; tax } \\ \text{noncompliance/evasion (wilful); } \\ \text{bribes/ kickbacks; insider trading } \\ \text{(not on firm’s account)} } \\ \end{array} $$
Operational loss refers to a gross monetary loss (excluding insurance or tax effects) resulting from an operational loss event. It includes all expenses associated with an operational loss event except for opportunity costs, forgone revenue, and costs related to risk management and control enhancements put in place to prevent future operational losses.
One of the hallmarks of the ideal OpRisk framework is a robust historical internal loss database. An institution must classify losses into the Basel categories and map them to its business units. The collection and maintenance of loss data are heavily regulated. Although Basel II regulations require firms to collect at least 5 years of data, (BCBS, 2006), most firms do not discard any data older than this limit. Losses are difficult to acquire and it may take years to build up a reliable and informative loss database. Consequently, most firms do not discard losses that they have suffered unless the business line in which this loss took place was sold and is no longer its constituent.
Data collection can be quite an uphill task because the data has to be collected in different formats and from different geographical locations and then channeled into a central repository. In addition, the firm must ensure that the data are secure and can be backed up and replicated in case of an accident.
Under Basel II regulations, financial institutions are allowed to select a loss threshold for loss of data collection. This means that for the loss event to be recorded and documented, it has to be at least as much as the threshold amount.
As expected, the threshold amount an institution chooses has significant implications on the risk profile of business units within it. OpRisk managers have to be careful not to set a threshold that’s either too low or too high. The following example illustrates this.
Bank Y’s loss experience in a given year is summarized in the table below. If the bank’s OpRisk department had chosen USD 100,000 as the threshold, built around the belief that only tail events drive OpRisk capital, that firm would think that its total loss in that year was approximately USD 54 million. And if the threshold choice was USD 20,000, the total losses would be approximately USD 59 million.
Notably, the sum of losses under USD 50,000 is about USD 24 million. That’s almost equivalent to the losses above USD 5 million (USD 26 million). For this particular firm, setting the loss collection threshold at USD 100,000 would result in total losses of USD 54 million. With a threshold of $0, actual losses would be USD 80 million, a situation that paints a significantly different risk profile.
$$ \begin{array}{l|c|c|c} \textbf{Loss brackets (USD)} & { \textbf{Number of } \\ \textbf{losses} } & \textbf{Total (USD)} & {\textbf{Accumulated total } \\ \textbf{(USD)}} \\ \hline {> 5,000,000} & {4} & {26,152,235} & {26,152,235} \\ \hline {1,000,000–5,000,000} & {8} & {12,520,500} & {38,672,735} \\ \hline {500,000–1,000,000} & {12} & {9,250,400} & {47,923,135} \\ \hline {100,000 –500,000} & {15} & {5,975,233} & {53,898,368} \\ \hline {50,000 –100,000} & {25} & {1,950,226} & {55,848,594} \\ \hline {20,000 –50,000} & {85} & {3,250,000} & {59,098,594} \\ \hline {< 20,000} & {1,402} & {20,452,860} & {79,551,454} \end{array} $$
As per Basel II rules (BCBS, 2006), OpRisk loss calculation and capital calculation should consider gross losses without giving any room for recoveries. The argument for not considering recoveries is that in these calculations, the firm is dealing with an event that, in terms of probabilities, happens once every thousand years. As such, it would not make sense to start applying mitigating factors to reduce the losses and eventually reduce capital, too.
A firm may be allowed to consider recoveries only in situations where it is possible to rapidly recover loss events. Rapidly recovered loss events are OpRisk events that lead to losses recognized in financial statements that are recovered over a short period. Consider the case of a bank that erroneously transfers money to a wrong party but recovers all or part of the loss soon thereafter. The bank may consider this to be a gross loss and a recovery. The actual loss is the gross loss less the recovered amount.
In situations where a firm is able to recover losses in full, the event is considered to be a “near miss”.
OpRisk events are usually complex and often have a large time gap between inception and final closure. Litigation cases arising from the 2007/2008 financial crisis provide the perfect example, where some cases went on for more than 5 years. In almost all legal systems, cases involving OpRisk events have a rather long life cycle that starts with a discovery phase in which lawyers and investigators are asked to prove whether the other party has a proper case to answer. During the discovery phase, the firms involved find it difficult to come up with an estimate for eventual losses since it is difficult to predict whether the case will terminate or proceed to full trial.
Even when a case “goes to trial,” proper loss estimation might not be possible at the early stages. Firms that find themselves embroiled in such litigation cases may set up reserves for potential losses. However, they usually do that only for a few weeks before the case is settled to avoid disclosure issues. For example, if the counterparty finds out the amount reserved, they may use this information in their favor).
In the latter stages of proceedings, a firm may be able to estimate its losses with a relatively greater degree of confidence. If the loss is large, setting up OpRisk capital can prove difficult because the inclusion of this settlement would cause some volatility in the capital. In some cases, the judge may end up ruling in the firm’s favor even after it has set aside a large loss reserve of, say, $1 billion. That, too, would still cause volatility in capital. For this reason, there’s need for firms to have a clear procedure on how to handle large, long-duration losses.
In a bid to have guidelines that firms can follow when dealing with OpRisk, accounting standards have been developed. IAS 37 – put together by the International Accounting Standards Board, defines and specifies the accounting for and disclosure of provisions, contingent liabilities, and contingent assets.
IAS37 establishes three specific applications:
According to IAS37, a firm must recognize a provision if, and only if:
Balance sheet provisions should be measured at the best estimate of the expenditure required to settle the present obligation at the balance sheet date. Provisions may take any future changes, such as changes in the law or technology, into account. This applies to instances where there is sufficient objective evidence that they will occur.
According to IAS37, the amount of the provision should not be reduced by gains from any of the following:
Reimbursements received post-settlement should be recognized as separate assets.
OpRisk can be viewed as a function of the control environment. Provided the control environment is fair and under control, large operational loss events are unlikely to be experienced, effectively keeping OpRisk under control. To put an effective control environment in place, the OpRisk manager has to master the firm’s business processes so as to be able to map the risks on these processes.
Firms use several tools to assess risk and report the many steps of the settlement process. This includes the use of Risk Control Self-Assessment (RCSA) and Key Risk Indicators (KRIS).
A risk control self-assessment (RCSA) serves as the foundation of a robust OpRisk framework. It requires departmental heads and risk managers to document risks and provide a rating system and control identification process.
Under RCSA, departmental heads and managers are seen as experts. The underlying argument is that they are the focal point of the flow of information and correspondence within a unit. As such, they are the persons best placed to understand the risks pertinent to their operations. Occasionally, a firm may also seek expert opinions from third parties.
Once RCSA is well established, risk reviews are usually done every 12 or 18 months and color-rated Red/Amber/Green (RAG), according to the perceived status.
A RCSA program is developed in three main steps:
Managers identify and assess inherent risks by making no inferences about controls embedded in the process. In other words, managers assume that there are no risk controls in place and then proceed to assess how risk manifests within the activities in the processes. During this process, managers seek to establish:
Risk metrics such as key risk indicators (KRIs), internal loss events, and external events, all contribute to the risk identification process. They ensure that an organization has considered all readily available data. At the end of the identification process, managers are able to have a birds’ eye view of the inherent risk of a firm’s business processes.
Managers then re-assess risk in the presence of controls to establish how effective the controls are at mitigating risk. At this stage, residual risk is measured. Residual risk is the probability of loss that remains after security measures or controls have been implemented.
Managers then embark on a control testing process to assess how effectively the controls in place mitigate potential operational risks.
For these reasons, there’s a need for independent review of the RCSA framework.
Key risk indicators seek to identify firm-specific conditions that could expose a firm to operational risk. KRIs are meant to provide firms with a system capable of predicting losses, giving a firm ample time to make the necessary adjustments. Examples of KRIs include:
The hope is that key risk indicators can identify potential problems and allow remedial action to be taken before losses are incurred.
For example, let’s consider the equity settlement process undertaken by an equity trading firm. An increase in the number of unsigned confirmations older than 30 days as a percentage of total confirmations above a certain threshold may be indicative of a developing underlying problem that needs to be addressed. Similarly, the number of disputed collateral calls may be a good KRI for the settlement process.
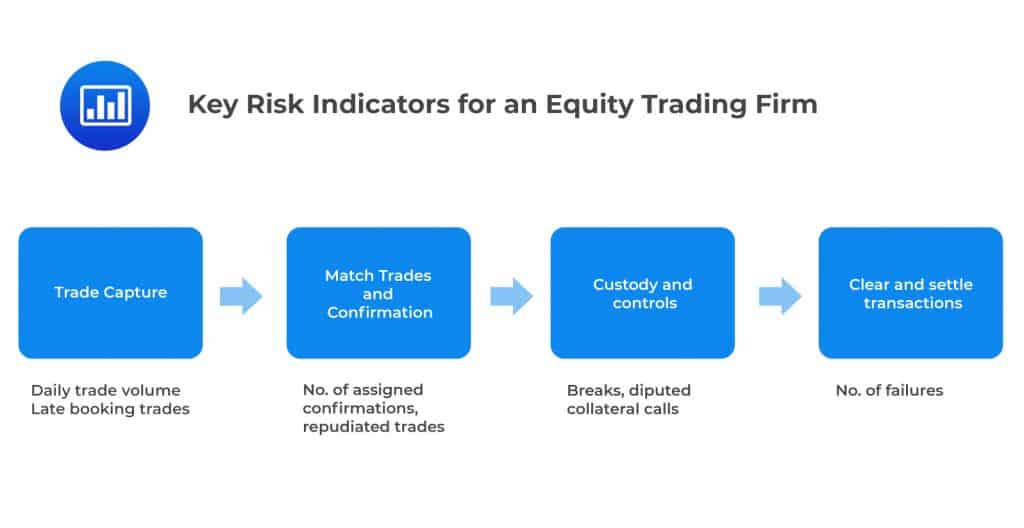 Collection of KRI data deserves special attention. To excel at unraveling the relationships between KRIs and losses, it is important that these data are absolutely reliable. One way to ensure data reliability is to automate the collection straight from a firm’s operational systems. It is equally crucial to note that the establishment of links between KRIs and losses may require a firm to carry out extensive data analysis. Besides, the implementation of the KRI program comes with costs. However, KRIs are arguably some of the most powerful tools used to measure operational risk.
Collection of KRI data deserves special attention. To excel at unraveling the relationships between KRIs and losses, it is important that these data are absolutely reliable. One way to ensure data reliability is to automate the collection straight from a firm’s operational systems. It is equally crucial to note that the establishment of links between KRIs and losses may require a firm to carry out extensive data analysis. Besides, the implementation of the KRI program comes with costs. However, KRIs are arguably some of the most powerful tools used to measure operational risk.
When a firm wishes to implement the use of KRIs, it must make assumptions about the OpRisk profile of the business. In an equity trading department, we might assume that the number of execution errors can be linked to the trade volume on the day, the number of securities that failed to be received or delivered, the number of employees available on the trading desk, the back office, and system downtime as measured by minutes offline. Next, the firm must establish the organizational level at which this relationship will be measured. It has to decide whether to measure this relationship at the department level or break everything down into specific product lines such as cash equities, listed derivatives, and OTC derivatives. All these decisions are fundamental to the success of the analysis.
In general, it is easier to find strong causal relationships at the lowest possible level. In our equity trading example, it may be easier to unearth local nuances, idiosyncrasies, and trends in the US cash equities department than modeling at the global equities division level.
$$ \begin{align*} \textbf{Table 9 –} & \textbf{Examples of Business Environment and Internal Control Environment} \\ & \textbf{Factors (BEICFs)} \end{align*} $$
$$ \begin{array}{l|l|l} \textbf{Business environment} & \textbf{Factor} & \textbf{Description} \\ \hline \text{Systems} & {\text{System downtime } \\ \text{System slow time } \\ \text{Software stability}} & {\text{Number of minutes a system is offline } \\ \text{Number of minutes a system is slow } \\ \text{Number of code lines changed in a program} } \\ \hline \text{Execution/Processing} & {\text{Transactions } \\ \text{Failed transactions } \\ \text{Data quality } \\ \text{Breaks} } & {\text{Number of transactions processed } \\ \text{Number of transactions that failed to settle } \\ \text{Ratio of transactions with errors } \\ \text{Number of transactions breaks} } \\ \hline \text{People/Organization} & {\text{Employees } \\ \text{Employees} \\ \text{experience} } & {\text{Number of employees } \\ \text{Average experience of} \\ \text{employees} } \\ \hline \text{Information Security} & \text{Malware attacks} & \text{Number of malware attacks } \\ \hline {} & \text{Hacking attempts} & \text{Number of hacking attempts} \end{array} $$
There may also be a link between OpRisk and External factors such as equity indexes and interest rates. For instance, higher volatility on stock markets leads to higher trading volumes, a situation which in turn brings about an increase in execution losses.
Scenario analysis is the process of evaluating a portfolio, project, or asset by changing various variables. These variables can be economic, market-based, industry-based, or company-specific. Scenario analysis is a useful tool in the operational risk framework since it helps a firm to explore the rare but plausible losses that could arise as a result of OpRisk events.
Unlike RCSA analysis, scenario analysis focuses on low probability high-impact events or “fat tail” events. The occurrence of these types of events can put a firm at serious risk. Scenario analysis is particularly helpful in situations where the firm is faced with an emerging risk with no previous loss experience.
Scenario analysis draws inputs from internal loss data, external data, expert opinions, or key risk indicators (KRIs). Large firms typically draw expert opinions from structured workshops. However, surveys and meetings with individual experts can also be used to gather expert advice. Studies have shown that most financial institutions analyze between 50 and 100 scenarios every year.
Expert opinion gained through scenario workshops is useful for OpRisk measurement and quantification efforts as long as it can be converted into numbers. The most commonly used technique involves gathering estimates on the loss frequencies on predefined severity brackets. These numbers are then converted to empirical distributions to model the probability of losses based on the amount of loss on an annual basis. The distribution is then used to inform decisions with regard to OpRisk reserving and capital management.
$$ \textbf{Figure 2 – Scenario Analysis Model for Loss Frequencies} $$
$$ \begin{array}{l|c|c} \textbf{Loss brackets (USD)} & { \textbf{Number of } \\ \textbf{losses} } & \textbf{Frequency} \\ \hline {> 5,000,000} & {5} & {1.7\%} \\ \hline {1,000,000–5,000,000} & {9} & {3.1\%} \\ \hline {500,000–1,000,000} & {13} & {4.5\%} \\ \hline {100,000 –500,000} & {17} & {5.9\%} \\ \hline {50,000 –100,000} & {27} & {9.3\%} \\ \hline {20,000 –50,000} & {89} & {30.7\%} \\ \hline {< 20,000} & {130} & {44.8\%} \\ \hline \text{Total} & {290} & {100\%} \end{array} $$
Presentation Bias: This arises when the order in which information is provided can skew or alter assessment from the experts.
Availability bias: The respondent may over/underestimate loss events due to limited risk experience. For example, a respondent who has had a 30-year career in FX trading but has never incurred an individual loss of USD 1 billion or more may be unable to accept the risk that such a loss would take place.
Anchoring bias: The expert may limit the range of a loss estimate based on personal experiences or knowledge of prior loss events,
Huddle bias or anxiety bias: When getting information from a group of experts, some individuals may tend to avoid conflicts that stem from differences of opinion. Such a decision may be informed by the fear of disrupting the smooth functioning of a group through dissent. More often than not, people are unwilling to disagree openly with those who are senior to them, experts, or powerful people in a group.
Gaming: Respondents may have interests that are in conflict with the goals of the workshop and may, therefore, intentionally withhold information or seek to influence outcomes.
Over/under confidence bias: This bias involves over/underestimation of risk due to the available experience and/or literature on the risk being limited.
Inexpert opinion: In many firms, scenario workshops do not attract the targeted expert. Such individuals may send in a more junior representative who has less expertise/experience.
As we have established, scenario analysis relies heavily on opinions gathered from experts. This poses a set of challenges:
The Delphi technique can solve all of these issues. But what exactly does it stand for?
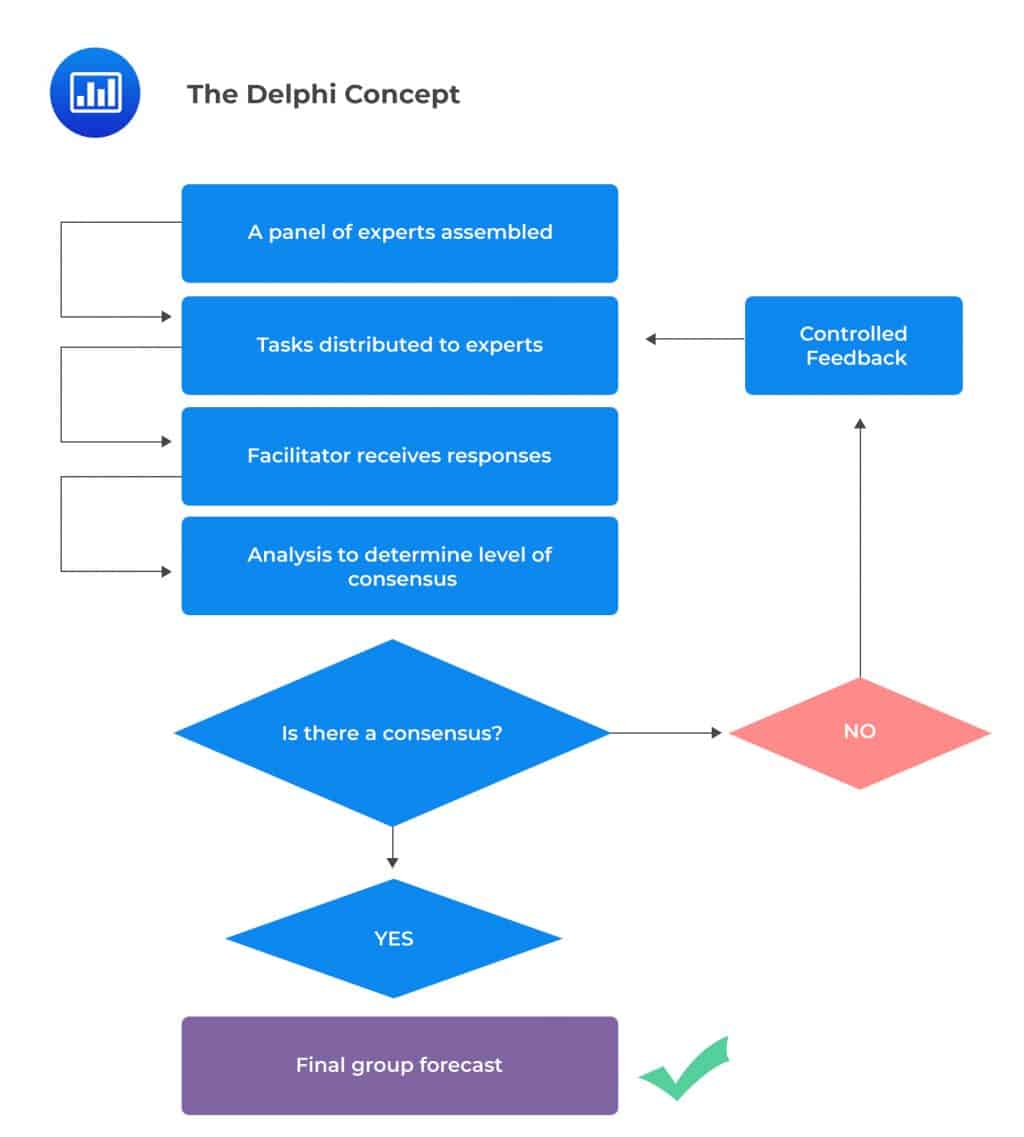
The Delphi technique (also known as Delphi procedure), is a method of congregating expert opinion through a series of iterative questionnaires in a bid to reach a group consensus. It is beneficial in situations where there is no true or definite answer to a problem.
The Delphi technique is built around the idea that forecasts made by a group of experts are generally more accurate than those made by individuals. The technique aims at using structured iteration to reach a consensus. A facilitator – usually one of the managers in charge of OpRisk – takes charge of the process.
The Delphi technique involves the following steps:
 Typical Operational Risk Profiles of Firms in Different Financial Sectors
Typical Operational Risk Profiles of Firms in Different Financial SectorsLarge financial institutions are usually made up of a number of business lines that have different OpRisk profiles. These include Corporate Finance, Trading and Sales, Retail Banking, Commercial Banking, Payment and Settlement, Agency Services, Asset Management, and Retail Brokerage.
We will now look at the OpRisk profiles of 5 of the main business lines: Corporate Finance, Trading and Sales, Retail Banking, Asset Management, and Retail Brokerage. Figure 3 shows the frequency of OpRisk events broken down with respect to the 7 level 1 categories of OpRisk. Figure 4 shows severity percentages based on total dollar amount losses.
$$ \textbf{Figure 3 – OpRisk Profiles Showing Frequency (%)} $$
$$ \begin{array}{l|c|c|c|c|c} \textbf{Event Type} & { \textbf{Trading } \\ \textbf{& Sales} } & { \textbf{Corporate } \\ \textbf{Finance} } & { \textbf{Retail } \\ \textbf{Banking} } & { \textbf{Asset } \\ \textbf{Management} } & { \textbf{Retail} \\ \textbf{Brokerage} } \\ \hline \text{Internal Fraud} & {1.0} & {1.6} & {5.4} & {1.5} & {5.8}\\ \hline \text{External Fraud} & {1.0} & {5.4} & \textbf{40.3} & {2.7} & {2.3}\\ \hline { \text{Employment} \\ \text{Practices} } & {3.1} & {10.1} & {17.6} & {4.3} & {4.4}\\ \hline { \text{Clients, Products,} \\ \text{& Business Practices} } & \textbf{12.7} & \textbf{47.1} & {13.1} & \textbf{13.7} & \textbf{66.9}\\ \hline { \text{Physical Asset} \\ \text{Damage} } & {0.4} & {1.1} & {1.4} & {0.3} & {0.1}\\ \hline { \text{Business Disruption } \\ \text{and System Failures} } & {5.0} & {2.2} & {1.6} & {3.3} & {0.5}\\ \hline { \text{Execution, Delivery } \\ \text{& Process } \\ \text{Management} } & \textbf{76.7} & \textbf{32.5} & \textbf{20.6} & \textbf{74.2} & \textbf{20.0} \end{array} $$
$$ \textbf{Figure 4 – OpRisk Profiles Showing Severity (%)} $$
$$ \begin{array}{l|c|c|c|c|c} \textbf{Event Type} & { \textbf{Trading } \\ \textbf{& Sales} } & { \textbf{Corporate } \\ \textbf{Finance} } & { \textbf{Retail } \\ \textbf{Banking} } & { \textbf{Asset } \\ \textbf{Management} } & { \textbf{Retail} \\ \textbf{Brokerage} } \\ \hline \text{Internal Fraud} & {11.0} & {0.24} & {6.3} & {11.1} & {18.1}\\ \hline \text{External Fraud} & {0.3} & {0.12} & {19.4} & {0.9} & {1.4}\\ \hline { \text{Employment} \\ \text{Practices} } & {2.3} & {0.59} & {9.8} & {2.5} & {6.3}\\ \hline { \text{Clients, Products,} \\ \text{& Business Practices} } & \textbf{29.0} & \textbf{93.67} & \textbf{40.4} & \textbf{30.8} & \textbf{59.5}\\ \hline { \text{Physical Asset} \\ \text{Damage} } & {0.2} & {0.004} & {1.1} & {0.2} & {0.1}\\ \hline { \text{Business Disruption } \\ \text{and System Failures} } & {1.8} & {0.02} & {1.5} & {0.1} & {0.2}\\ \hline { \text{Execution, Delivery } \\ \text{& Process } \\ \text{Management} } & \textbf{55.3} & \textbf{5.4} & \textbf{21.4} & \textbf{52.8} & \textbf{14.4} \end{array} $$
This category is dominated by EDPM in terms of both frequency and severity. The risk profile is reflective of a business model where traders perform trades on behalf of either their own firms or clients. These trades are settled by exchanging securities against some form of payment. However, products are diverse and complex and settlements deadlines and procedures vary significantly. As such, the major OpRisk is execution, and that’s where most of the loss occurs.
Under corporate finance, the business basically provides consultancy services where it advises corporations on matters such as funding, capital structuring, mergers & acquisitions, and investment decisions. Most of the losses are incurred in the form of “litigation” or disputes with clients for arguably poor advice when, for example, mergers go wrong.
The OpRisk profile of retail banks bears a lot of semblance to that of the retail brokerage; External fraud constitutes the highest frequency of OpRisk events that tend to happen on a daily basis. Execution comes in a distant second. However, the most severe loss events come under litigation.
In the years leading up to the financial crisis of 2007–2009, asset management firms enjoyed steady increases in assets under management (AUM). The markets at the time were bullish and most assets registered good year-on-year profits. In that period, therefore, operational costs were largely an afterthought for many asset managers. Errors and high operating costs were obscured under the increased revenues from a larger asset base and big profits that came from high returns in the world markets.
But after the crisis, AUM reduced by as much as 40%, in part because there were no risk controls. These losses prompted asset managers to focus on previously ignored product characteristics, including costs related to OpRisk. The recovery process for Asset Management has been extremely slow. So much so that even in 2012, most of the growth of asset management was down to market appreciation and not due to an increase in the flow of resources from clients. Many investors retiring in just a few more years lost their pensions because of (I) poor market conditions, and (II) a lack of caution and risk management from pension fund managers. Since then, OpRisk management has become a key part of asset management, with risk managers putting in place risk controls meant to reduce costs.
Although asset managers are susceptible to all forms of risks, namely OpRisk, market, and credit risks, OpRisk is typically the largest risk exposure an asset manager has.
Common OpRisk events include:
Failure to comply with local regulations or basic business ethics can bring about large operational losses and serious reputational damage.
The OpRisk profile for asset management firms reveals the largest frequency and severity percentage fall under the Execution, Delivery, and Process Management risk category.
Generally, risk profiles tend to vary significantly between institutions because each institution adopts its own unique business strategies. This notwithstanding, the risk profile of broker-dealers is usually dominated by OpRisk. Research shows OpRisk accounts for at least 60–70% of the total risk capital in retail brokerage firms.
In recent years, more and more brokerage firms have ditched brick-and-mortar establishments in favor of online business. This has enabled them to offer clients the convenience of trading from home or work. It has also paved way for more competitive pricing and other creative products designed to give a firm a competitive edge, e.g. free online research tools. Most of the surviving brick-and-mortar brokers are part of larger financial institutions, which tend to focus on wealthier customers that are prepared to pay higher fees in exchange for personalized services.
The move to the online business model has coincided with the invention of sophisticated, high-speed trading technology that has changed the way broker-dealers trade for their own accounts and as agents for their customers. Under the new model, hedge funds, mutual funds, banks, insurance companies, as well as individual customers are able to use the broker-dealer’s market participant identifier (MPID) to electronically access the exchange. This has greatly increased the operational risk for broker-dealers as they bear responsibility for all transactions executed with their MPID. If the broker-dealer does not make use of pre-trade risk management controls, commonly referred to as filters, then the risks are even greater.
How sensitive is the online model to OpRisk? You might ask. With today’s advanced technology, broker-dealer systems can accommodate more than 1000 orders per second. Even a short-lived system malfunction can result in financially devastating effects. For example, let’s assume a bug triggers an algorithm malfunction that erroneously places repetitive orders with an average size of 200 shares and an average price of USD 50. If that happens, just a two-minute delay in the detection of the problem could result in the entry of, say, 120,000 orders valued at USD120 million.
Compared to other business lines, insurers are still in the early stages of the development of their OpRisk frameworks. This is surprising somewhat because, in recent years, insurers have suffered several large, highly publicized operational losses:
Given these and many more high-profile loss events, it is not surprising that insurers have been more diligent with regard to OpRisk. There has been significant progress in their attempts to come up with robust OpRisk management frameworks to catch up with banks. However, the insurance business still lags far behind compared to banking on matters OpRisk management.
Governance and organizational design play a critical role toward the development and success of an OpRisk framework at a firm. The development of OpRisk controls, scenario analysis, key risk indicators, and other tools are important, but for all these to be implemented and work as envisioned, there has to be a support all the way from the firm’s top brass. The board of directors and senior management have to take the initiative and ensure that everyone buys into the OpRisk framework and knows what’s expected of them.
Let’s now look at a few organizational designs and the beliefs that firms need to have to make them work:
In this organizational design, the risk manager acts as more of a facilitator or coordinator of risk management. The risk manager gathers information and reports directly to the CEO or the Board of directors. OpRisk management is carried out by a small central risk group.
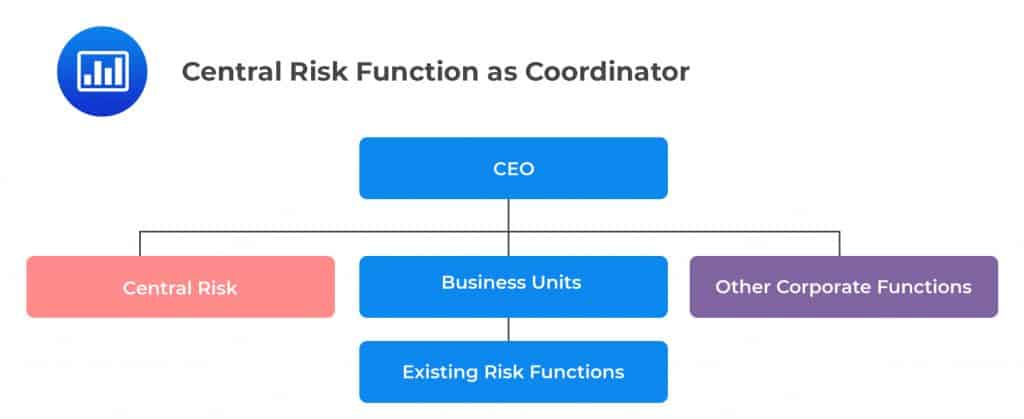 Regulators are generally not comfortable with this structure because they believe that there are conflicts of interest in any arrangement that requires risk managers to report to senior management or other stakeholders tasked with the maximization of shareholder wealth.
Regulators are generally not comfortable with this structure because they believe that there are conflicts of interest in any arrangement that requires risk managers to report to senior management or other stakeholders tasked with the maximization of shareholder wealth.
In order for this structure to be successful, business units have to be responsive to the demands of the Central Risk Group without being influenced by senior management who have control over employee remuneration and other compensation packages.
In this organizational design, there exists a dotted line between risk managers and the Central Risk function. However, risk managers are appointed by senior management who retain control over compensation decisions.
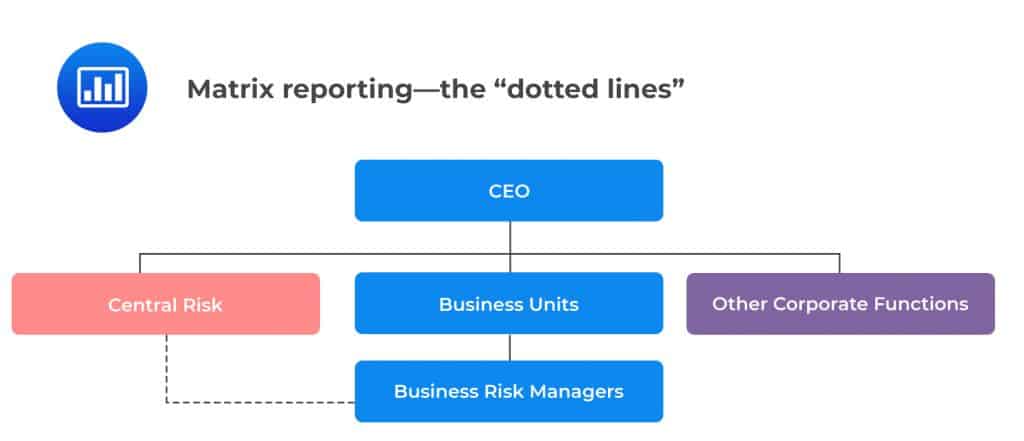 In order for this to be successful, the business units should nurture a strong risk culture and work closely with the Central Risk function. This design is preferred when there is a culture of distrust of the central risk function based on historical events.
In order for this to be successful, the business units should nurture a strong risk culture and work closely with the Central Risk function. This design is preferred when there is a culture of distrust of the central risk function based on historical events.
In this structure, risk managers still maintain a physical presence in the business units but report to the Central Risk function, usually based in the headquarters. It is a considerably popular design within large firms.
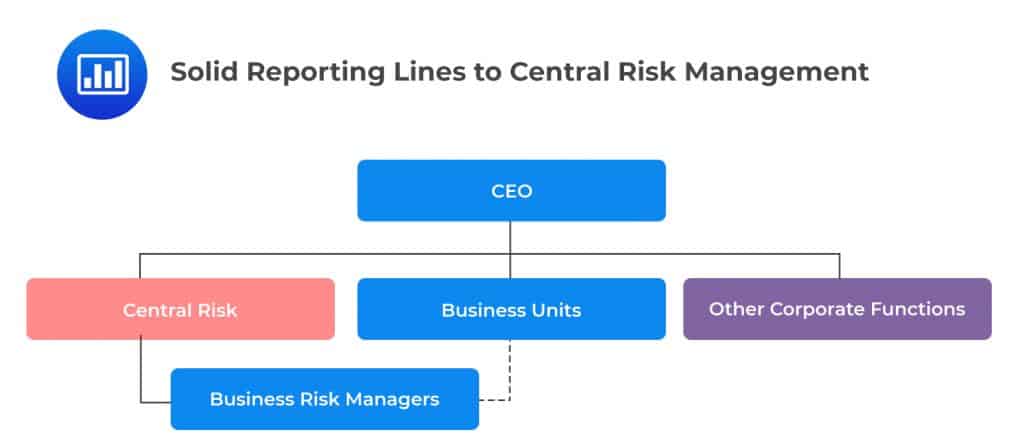 The design gives the Central Risk function the ability to prioritize risk management efforts across different initiatives. This solid line reporting helps to establish a more homogenous risk culture and consistent approach across the enterprise.
The design gives the Central Risk function the ability to prioritize risk management efforts across different initiatives. This solid line reporting helps to establish a more homogenous risk culture and consistent approach across the enterprise.
This design is built around the central chief risk officer who is in charge of risk management across a firm. The central chief risk officer is tasked with monitoring and managing all of the firm’s risks. They report to senior management and Board.
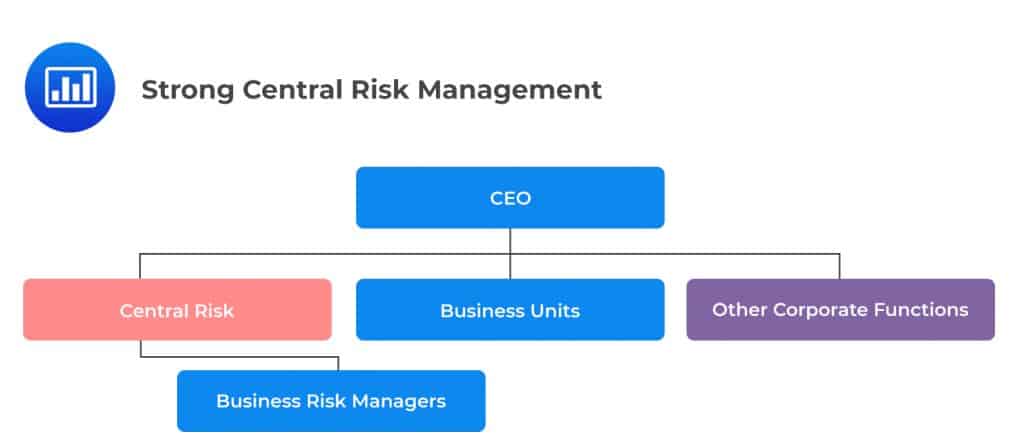 In recent years, this has been the preferred design for most large firms, either by internal agreement or through regulatory pressure. It gives the regulator an easy time as they supervise the implementation of the established risk management requirements. Rather than working with multiple business units scattered across many business units, the regulator is able to focus on one particular group based in a single geographical area.
In recent years, this has been the preferred design for most large firms, either by internal agreement or through regulatory pressure. It gives the regulator an easy time as they supervise the implementation of the established risk management requirements. Rather than working with multiple business units scattered across many business units, the regulator is able to focus on one particular group based in a single geographical area.
Practice Question
As a manager of an organization, it is important to ask yourself questions during risk control self-assessment. Which of the following is not a necessary concern?
A. Risk scenario: Where are the potential weak points on each of these processes?
B. Exposure: How big a loss could happen to my operation in the event of a failure?
C. Delivery: How can we better handle customer delivery?
D. Performance: How could failure change my organization’s reputation of financial performance?
The correct answer is C.
Insofar as risk goes, it’s important to ask important questions that can help mitigate the risk. A question such as “how can we better handle customers’ delivery?” is not one of them. Asking questions on different risk scenarios and exposure is necessary for combating risks that are likely to occur:
Risk scenario: Where are the potential weak points on each of these processes?
Exposure: How big a loss could happen to my operation in the event of a failure?
Performance: How could a failure change my organization’s reputation and financial performance?
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.