




Defining Properties of Probability

Simple random sampling, also called chance selection, refers to a method of sample collection in which each element in the population is given an equal chance of being included in the sample. In other words, all the elements in the population have equal probabilities of being chosen. The method assumes that if the population is sufficiently large and the sample is chosen purely on a random basis, the sample is likely to represent all the groups in the population.
Assume that we want to come up with a sample of 50 CFA Level 1 candidates, given that there are 5000 Level 1 candidates in total.
One approach may involve numbering each of the 5000 candidates, placing the numbers in a basket and shaking the basket to jumble them up. Next, we would randomly draw 50 numbers from the basket, one after the other, without replacement.
A more scientific approach may also involve the use of random numbers where all the 5000 candidates are numbered in a sequence (from 1 to 5000). We may then use a computer to randomly generate 50 numbers between 1 and 5000, where a given number represents a particular candidate who can be identified by their name or admission number.
The underlying feature in random sampling is that each element in the population must have equal chances of being chosen. buy xanax com https://urbanyogaphx.com/ alprazolam tablet buy online
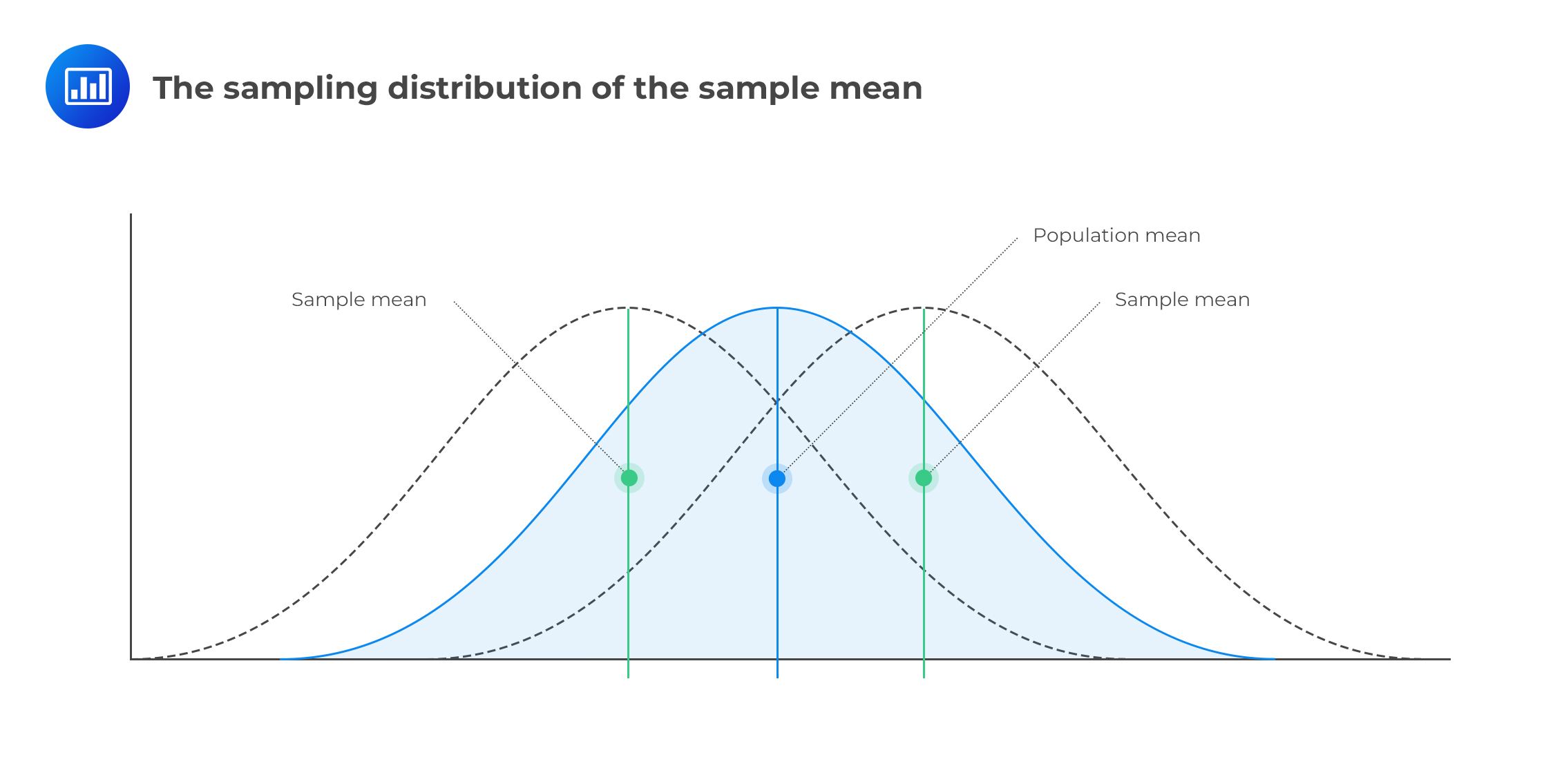
Sampling distribution refers to the distribution of possible outcomes of a sample statistic, such as the mean that would be derived from equally-sized samples drawn from the same population. It’s a probability distribution of a sample statistic from multiple samples.
If we wish to estimate the mean return on 1000 different stocks in a country, we could select a sample of 50 stocks and analyze their financial results to calculate the sample mean return. Suppose we repeatedly selected equally-sized samples from the population, we would end up with several different estimates of the unknown population mean return. The distribution of these sample means would effectively give us the sampling distribution of the mean.
One condition stands: the different samples should be equally-sized and drawn from the same population. This would ensure that the results are reliable and relevant.






Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.