






Interest Rates
After completing this reading, you should be able to: Calculate and interpret the... Read More
After completing this reading, you should be able to:
Unlike linear regression, multiple regression simultaneously considers the influence of multiple explanatory variables on a response variable Y. In other words, it permits us to evaluate the effect of more than one independent variable on a given dependent variable.
The form of the multiple regression model (equation) is given by:
$$Y_i = β_0 + β_1 X_1i + β_2 X_2i + … + β_k X_ki + ε_i \quad ∀i = 1, 2, … n$$
Intuitively, the multiple regression model has k slope coefficients and k+1 regression coefficients. Normally, statistical software (such as Excel and R) are used to estimate the multiple regression model.
The slope coefficients \({\beta}_k\) computes the level of variation of the dependent variable Y when the independent variable \(X_j\) changes by one unit while holding other independent variables constant. The interpretation of the multiple regression coefficients is quite different compared to linear regression with one independent variable. The effect of one variable is explored while keeping other independent variables constant.
For instance, a linear regression model with one independent variable could be estimated as \(\hat{Y}=0.6+0.85X_1\). In this case, the slope coefficient is 0.85, which implies that a 1 unit increase in X1 results in 0.85 units increases independent variable Y.
Now, assume that we had the second independent variable to the regression so that the regression equation is \(\hat{Y}=0.6+0.85X_1+0.65X_2\). A unit increase in X1 will not result in a 0.85 unit increase in Y unless X1 and X2 are uncorrelated. Therefore, we will interpret 0.85 as one unit of X1 leads to 0.85 units increase in the dependent variable Y, while keeping X2 constant.
Although the multiples regression parameters can be estimated, it is challenging since it involves a huge amount of algebra and the use of matrices. However, we build a foundation of understanding using the multiple regression model with two explanatory variables.
Consider the following multiples regression equation.
$$Y_i = β_0 + β_1 X_1i + β_2 X_2i+ε_i$$
The OLS estimator of β1 is estimated as follows:
The first step is to regress X1 and X2 and to get the residual of \(X_{1i}\) given by:
$${\epsilon}_{X_{1i}}=X_{1i}-{\hat{\alpha}}_{0}-{\hat{\alpha}}_{1}X_{2i}$$
Where \(\hat{α} _0\) and \(\hat{α} _1\) are the OLS estimators of \(X_{2i}\).
The next step is to regress Y on X2 to get the residuals of Yi, which is intuitively given by:
$${\epsilon}_{Y_i }=Y_i-{\hat{y} _0}-{\hat{y}} _{1} X_{2i}$$
Where \({\hat{γ}} _0\) and \({\hat{γ}} _1\) are the OLS estimators of \(X_{2i}\). The final step is to regress the residual of X1 and Y \( (ϵ_{X_{1i}} \text{ and } ϵ_{Y_i }) \) to get:
$$ϵ_{Y_i }=\hat{β} _1 ϵ_{X_{1i} }+ϵ_i $$
Note that we do not have a constant, the expected values of \(ϵ_{Y_i }\) and \(ϵ_{X_i }\) are both 0. Moreover, the main purpose of the first and the second regression is to exclude the effect of X2 from both Y and X1 by dividing the variable into the fittest value which is correlated with X2, and the residual error which is uncorrelated with X2 and thus the two-residual obtained is uncorrelated with X2 by intuition. The last step of the regression gives the regression between the components of Y and X1, which is uncorrelated with X2.
The OLS estimator for \(β_2\) can be approximated analogously as that of \(β_1\) by exchanging X2 for X1 in the process above. By repeating this process, we can estimate a k-parameter model such as:
$$Y_i = β_0 + β_1 X_{1i} + β_2 X_{2i} + … + β_k X_{ki} + ε_i ∀i = 1, 2, \dots n$$
Most of the time, this is done using a statistical package such as Excel and R.
Suppose that we have n observations of the dependent variable (Y) and the independent variables (X1, X2, . . . , Xk), we need to estimate the equation:
$$Y_i = β_0 + β_1 X_{1i} + β_2 X_{2i} + … + β_k X_{ki} + ε_i \quad ∀i = 1, 2, \dots n$$
For us to make a valid inference from the above equation, we need to make classical normal multiple linear regression model assumptions as follows:
The assumptions are almost the same as those of linear regression with one independent variable, only that the second assumption is tailored to ensure no linear relationships between the independent variables (multicollinearity).
The goodness of fit of a regression is a measure using the Coefficient of determination (\(R^2\)) and the adjusted coefficient of determination.
Recall that the standard error estimate gives a percentage at which we are certain of a forecast made by a regression model. However, it does not tell us how suitable is the independent variable in determining the dependent variable. The coefficient of variation corrects this shortcoming.
The coefficient of variation measures a proportion of the total change in the dependent variable explained by the independent variable. We can calculate the coefficient of variation in two ways:
The coefficient of variation can be computed by squaring the correlation coefficient (r) between the dependent and independent variables. That is:
$$R^{2}=r^{2}$$
Recall that:
$$r=\frac{Cov(X,Y)}{{\sigma}_{X}{\sigma}_{Y}}$$
Where
\(Cov(X, Y)\)-covariance between two variables, X and Y
\(σ_X\)-standard deviation of X
\(σ_Y\)-standard deviation of Y
However, this method only accommodates regression with one independent variable.
The correlation coefficient between the money supply growth rate (dependent, Y) and inflation rates (independent, X) is 0.7565. The standard deviation of the dependent (explained) variable is 0.050, and that of the independent variable is 0.02. Regression analysis for the ten years was conducted on this variable. We need to calculate the coefficient of determination.
Solution
We know that:
$$r=\frac{Cov(X,Y)}{{\sigma}_{X}{\sigma}_{Y}}=\frac{0.0007565}{0.05\times 0.02}=0.7565$$
So, the coefficient of determination is given by:
$$r^{2}=0.7565^2 =0.5723=57.23%$$
So, in regression, the money supply growth rate explains roughly 57.23% of the variation in the inflation rate over the ten years.
If the regression analysis is known, then our best estimate for any observation for the dependent variable would be the mean. Alternatively, instead of using the mean as an estimate of Yi, we can predict an estimate using the regression equation. The resulting solution will be denoted as:
$$Y_i = β_0 + β_1 X_1i + β_2 X_2i + … + β_k X_ki + ε_i=\hat{Y} _i+\hat{ϵ} _i$$
So that:
$$Y_i=\hat{Y} _i+\hat{ϵ} _i$$
Now if we subtract the mean of the dependent variable in the above equation and square and sum on both sides so that:
$$\begin{align*}\sum_{i=1}^{n}{\left(Y_i -\bar{Y}\right)^2}&=\sum_{i=1}^{n}{\left(\hat{Y}_i -\bar{Y}+\hat{\epsilon}_i\right)^2}\\&=\sum_{i=1}^{n}{\left(\hat{Y}_i -\bar{Y}\right)^2}+2\sum_{i=1}^{n}{\hat{\epsilon}_{i} \left(\hat{Y}_i -\bar{Y}\right)}+\sum_{i=1}^{n}{\hat{\epsilon}_{i}^2}\end{align*}$$
Note that:
$$2\sum_{i=1}^{n}{\hat{\epsilon}_{i} \left(\hat{Y}_i -\bar{Y}\right)}=0$$
Since the sample correlation between \(\hat{Y} _i\) and \(\hat{\epsilon} _i\)is 0. The expression, therefore, reduces to,
$$\sum_{i=1}^{n}{\left(Y_i -\bar{Y}\right)^2}=\sum_{i=1}^{n}{\left(\hat{Y}_i -\bar{Y}\right)^2}+\sum_{i=1}^{n}{\hat{\epsilon}_{i}^2}$$
But
$$\hat{\epsilon}^{2}_{i}=\left(Y_i -\hat{Y}\right)^2$$
So, that
$$\sum_{i=2}^{n}{\hat{\epsilon}_{i}^{2}}=\sum_{i=1}^{n}{\left(Y_i -\hat{Y}\right)^2}$$
Therefore,
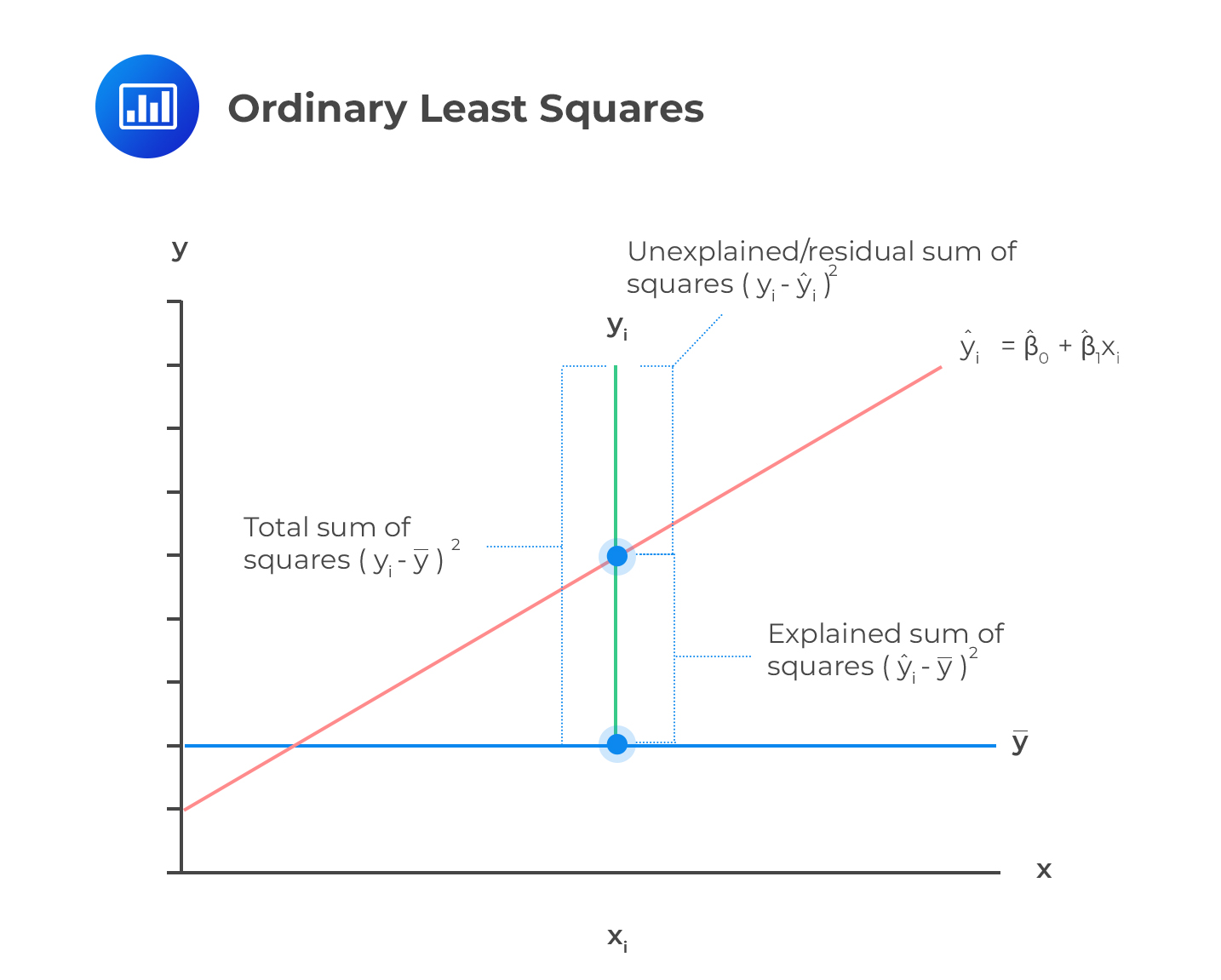
$$\sum_{i=1}^{n}{\left(Y_i -\bar{Y}\right)^2}=\sum_{i=1}^{n}{\left(\hat{Y}_i -\bar{Y}\right)^2}+\sum_{i=1}^{n}{\left(Y_i -\hat{Y}\right)^2}$$
If the regression analysis is useful for predicting Yi using the regression equation, then the error should be smaller than predicting Yi using the mean.
Now let:
Explained Sum of Squares (ESS)=\(\sum_{i=1}^{n} {\left(\hat{Y}_i -\bar{Y}\right)^2}\)
Residual Sum of Squares (RSS) =\(\sum_{i=1}^{n} {\left(Y_i -\hat{Y}\right)^2}\)
Total Sum of Squares (TSS)=\(\sum_{i=1}^{n} {\left(Y_i -\bar{Y}\right)^2}\)
Then:
$$TSS=ESS +RSS$$
If we divide both sides by TSS, we get:
$$\begin{align*}1&=\frac{ESS}{TSS} +\frac{RSS}{TSS}\\&⇒\frac{ESS}{TSS}=1-\frac{RSS}{TSS}\end{align*}$$
Now, recall than the coefficient of determination is the fraction of the overall change that is reflected in the regression. Denoted by R2, coefficient of determination is given by:
$$R^2 =\frac{\text{Explained Variation}}{\text{Total Variation}}=\frac{ESS}{TSS}=1-\frac{RSS}{TSS}$$
 If a model does not explain any of the observed data, then it has an \(R^2\) of 0 . On the other hand, if the model perfectly describes the data, then it has an \(R^2\) of 1. Other values are in the range of 0 and 1 and are always positive. For instance, in the above example, the \(R^2\) is approximately 1 and thus, the money supply growth rate perfectly explains the level of inflation rates in the countries.
If a model does not explain any of the observed data, then it has an \(R^2\) of 0 . On the other hand, if the model perfectly describes the data, then it has an \(R^2\) of 1. Other values are in the range of 0 and 1 and are always positive. For instance, in the above example, the \(R^2\) is approximately 1 and thus, the money supply growth rate perfectly explains the level of inflation rates in the countries.
Considering the first limitation, we now discuss the adjusted \(R^2\).
Denoted by \(\bar{R} ^2\), the adjusted-R2 measures the goodness of fit, which does not automatically increase if an independent variable is added to the model; that is, it is adjusted for the degrees of freedom. Note that \(\bar{R} ^2\) is produced by statistical software. The relationship between the R2 and \(\bar{R} ^2\) is given by:
$$\bar{R}^2 =1-\frac{\left(\frac{RSS}{n-k-1}\right)}{\left(\frac{TSS}{n-1}\right)}$$
$$=1-\left(\frac{n-1}{n-k-1}\right)\left(1-R^2\right)$$
Where
n=number of observations
k=number of the independent variables (Slope coefficients)
The adjusted R-squared can increase, but that happens only if the new variable improves the model more than would be expected by chance. If the added variable improves the model by less than expected by chance, then the adjusted R-squared decreases.
When k≥ 1, then \(R^2>\bar{R}^2\) since adding an extra new independent variable results in a decrease in \(\bar{R}^2\) if that addition causes a small increase in \(R^2\). This explains the fact that \(\bar{R}^2\) can be a negative though \(R^2\) is always nonnegative.
A point to note is that when we decide to use \(\bar{R}^2\) to compare the regression models, the dependent variable is defined the same way and that the sample size is the same as that of \(R^2\).
The following are the factors to watch out for when guarding against applying the \(R^2\) or the \(\bar{R}^2\):
\(\bar{R}^2\) does not automatically indicate that regression is well specified due to its inclusion of a right set of variables since a high \(\bar{R}^2\) could reflect other uncertainties in the data in the analysis. Moreover, \(\bar{R}^2\) can be negative if the regression model produces an extremely poor fit.
Previously, we had conducted hypothesis tests on individual regression coefficients using the t-test. We need to perform a joint hypothesis test on the multiple regression coefficients using the F-test based on the F-statistic.
In multiple regression, we cannot test the null hypothesis that all the slope coefficients are equal to 0 using the t-test. This is because an individual test on the coefficient does not accommodate the effect of interactions among the independent variables (multicollinearity).
F-test (test of regression’s generalized significance) determines whether the slope coefficients in multiple linear regression are all equal to 0. That is, the null hypothesis is stated as\(H_0:β_1=β_2 = … =β_K= 0\) against the alternative hypothesis that at least one slope coefficient is not equal to 0.
To accurately compute the test statistic for the null hypothesis that the slope is equal to 0, we need to identify the following:
I. The Sum of Squared Residuals (SSR) given by:
$$\sum_{i=1}^{n} {\left(Y_i -\hat{Y}_i\right)^2}$$
This is also called the residual sum of squares.
II.Explained Sum of Squares (ESS) given by:
$$\sum_{i=1}^{n} {\left(\hat{Y}_i -\bar{Y}_i\right)^2}$$
III. The total number of observations (n).
III. The number of parameters to be estimated. For example, in a regression analysis with one independent variable, there are two parameters: the slope and the intercept coefficients.
Using the above four requirements, we can determine the F-statistic. The F-statistic measures how effective the regression equation explains the changes in the dependent variable. The F-statistic is denoted by F(Number of slope parameters, n-(number of parameters)). For instance, the F-statistic for multiple regression with two slope coefficients (and one intercept coefficient) is denoted as F2, n-3. The value n-3 represents the degrees of freedom for the F-statistic.
The F-statistic is the ratio of the average regression sum of squares to the average amount of squared errors. The average regression sum of squares is the regression sum of squares divided by the number of slope parameters (k) estimated. The average sum of squared errors is the sum of squared errors divided by the number of observations (n) less a total number of parameters estimated ((n – (k + 1)). Mathematically:
$$F=\frac{\text{Average regression sum of squares}}{\text{The average sum of squared errors}}$$
$$=\frac{\frac{\text{Explained sum of squares}}{\text{ESS Slope parameters estimated}}}{\frac{\text{Sum of squared residuals (SSR)}}{n-\text{number of parameters estimated}}}$$
In this case, we are dealing with a multiple linear regression model with k independent variable whose F-statistic is given by:
$$F=\frac{\left(\frac{ESS}{k}\right)}{\left(\frac{SSR}{n-(k+1)}\right)}$$
In regression analysis output (ANOVA part), MSR and MSE are displayed as the first and the second quantities under the MSS (mean sum of the squares) column, respectively. If the overall regression’s significance is high, then the ratio will be large.
If the independent variables do not explain any of the variations in the dependent variable, each predicted independent variable \(\hat{Y}_i )\) possesses the mean value of the dependent variable \((Y)\). Consequently, the regression sum of squares is 0 implying the F-statistic is 0.
So, how do we decide F-test? We reject the null hypothesis at α significance level if the computed F-statistic is greater than the upper α critical value of the F-distribution with the provided numerator and denominator degrees of freedom (F-test is always a one-tailed test).
An analyst runs a regression of monthly value-stock returns on four independent variables over 48 months.
The total sum of squares for the regression is 360, and the sum of squared errors is 120.
Test the null hypothesis at a 5% significance level (95% confidence) that all the four independent variables are equal to zero.
$$H_0:β_1=0,β_2=0,…,β_4=0$$
Versus
$$ H_1:β_j≠0 \text{(at least one j is not equal to zero, j=1,2… k )} $$
ESS = TSS – SSR = 360 – 120 = 240
The calculated test statistic:
$$F=\frac{\left(\frac{ESS}{k}\right)}{\left(\frac{SSR}{n-(k+1)}\right)}=\frac{\frac{240}{4}}{\frac{120}{43}}=21.5$$
\(F_{4,43}^3\) is approximately 2.59 at a 5% significance level.
Decision: Reject H0.
Conclusion: at least one of the 4 independent variables is significantly different than zero.
An investment analyst wants to determine whether the natural log of the ratio of bid-offer spread to the price of a stock can be explained by the natural log of the number of market participants and the amount of market capitalization. He assumes a 5% significance level. The following is the result of the regression analysis.
$$\begin{array}{l|c|c|c} & \textbf{Coefficient} & \textbf{Standard Error} & \textbf{t-Statistic} \\ \hline \text{Intercept } & 1.6959 & 0.2375 & 7.0206 \\ \text{Number of market participants} & -1.6168 & 0.0708 & -22.8361 \\ \text{Amount of Capitalization} & -0.4709 & 0.0205 & -22.9707 \end{array}$$
$$\begin{array}{l|c|c|c} \textbf{ANOVA} & \textbf{df} & \textbf{SS} & \textbf{MSS} & \textbf{F} & \textbf{Significance F} \\ \hline \text{Regression} & 2 & 3,730.1534 & 1,865.0767 & 2,217.95 & 0.00 \\ \text{Residual} & 2,797 & 2,351.9973 & 0.8409 & & \\ \text{Total} & 2,799 & 5,801.2051 & & & \end{array}$$
$$ \begin{array}{lc} \text{Residual standard error} & 0.9180 \\ \text{Multiple R-squared} & 0.6418 \\ \text{Observations}& 2,800 \end{array} $$
We are concerned with the ANOVA (Analysis of variance) results. We need to conduct F-test to determine the significance of regression analysis.
Solution
So, the hypothesis is stated as:
$$H_0 :\hat{\beta}_1 =\hat{\beta}_2=0$$
vs
$$H_1: \text{At least 1} \hat{β} _j≠0, ∀ j=1,2$$
There are two slope coefficients, k=2 (coefficients on the natural log of the number of market participants and the amount of market capitalization), which is degrees of freedom for the numerator of the F-statistic formula. For the denominator, the degrees of freedom are n- (k + 1) =2800-3= 2,797.
The sum of the squared errors is 2,351.9973, while the regression sum of squares is 3,730.1534. Therefore, the F-statistic is:
$$F_{2,2797}=\frac{\left(\frac{ESS}{k}\right)}{\left(\frac{SSR}{n-(k+1)}\right)}=\frac{\frac{3730.1534}{2}}{\frac{2351.9973}{2797}}=2217.9530$$
Since we are working at a 5% (0.05) significance level, we look at the F-distribution table on the second column which displays the F-distributions with degrees of freedom in the numerator of the F-statistic formula as seen below:
$$\textbf{F Distribution: Critical Values of F (5% significance level)}$$
$$\begin{array}{l|llllllllll}
& \textbf{1} & \textbf{2} & \textbf{3} & \textbf{4} & \textbf{5} & \textbf{6} & \textbf{7} & \textbf{8} & \textbf{9} & \textbf{10} \\ \hline
\textbf{10} & 4.96 & 4.10 & 3.71 & 3.48 & 3.33 & 3.22 & 3.14 & 3.07 & 3.02 & 2.98 \\
\textbf{11} & 4.84 & 3.98 & 3.59 & 3.36 & 3.20 & 3.09 & 3.01 & 2.95 & 2.90 & 2.85 \\
\textbf{12} & 4.75 & 3.89 & 3.49 & 3.26 & 3.11 & 3.00 & 2.91 & 2.85 & 2.80 & 2.75 \\
\textbf{13} & 4.67 & 3.81 & 3.41 & 3.18 & 3.03 & 2.92 & 2.83 & 2.77 & 2.71 & 2.67 \\
\textbf{14} & 4.60 & 3.74 & 3.34 & 3.11 & 2.96 & 2.85 & 2.76 & 2.70 & 2.65 & 2.60 \\
\textbf{15} & 4.54 & 3.68 & 3.29 & 3.06 & 2.90 & 2.79 & 2.71 & 2.64 & 2.59 & 2.54 \\
\textbf{16} & 4.49 & 3.63 & 3.24 & 3.01 & 2.85 & 2.74 & 2.66 & 2.59 & 2.54 & 2.49 \\
\textbf{17} & 4.45 & 3.59 & 3.20 & 2.96 & 2.81 & 2.70 & 2.61 & 2.55 & 2.49 & 2.45 \\
\textbf{18} & 4.41 & 3.55 & 3.16 & 2.93 & 2.77 & 2.66 & 2.58 & 2.51 & 2.46 & 2.41 \\
\textbf{19} & 4.38 & 3.52 & 3.13 & 2.90 & 2.74 & 2.63 & 2.54 & 2.48 & 2.42 & 2.38 \\
\textbf{20} & 4.35 & 3.49 & 3.10 & 2.87 & 2.71 & 2.60 & 2.51 & 2.45 & 2.39 & 2.35 \\
\textbf{21} & 4.32 & 3.47 & 3.07 & 2.84 & 2.68 & 2.57 & 2.49 & 2.42 & 2.37 & 2.32 \\
\textbf{22} & 4.30 & 3.44 & 3.05 & 2.82 & 2.66 & 2.55 & 2.46 & 2.40 & 2.34 & 2.30 \\
\textbf{23} & 4.28 & 3.42 & 3.03 & 2.80 & 2.64 & 2.53 & 2.44 & 2.37 & 2.32 & 2.27 \\
\textbf{24} & 4.26 & 3.40 & 3.01 & 2.78 & 2.62 & 2.51 & 2.42 & 2.36 & 2.30 & 2.25 \\
\textbf{25} & 4.24 & 3.39 & 2.99 & 2.76 & 2.60 & 2.49 & 2.40 & 2.34 & 2.28 & 2.24 \\
\textbf{26} & 4.22 & 3.37 & 2.98 & 2.74 & 2.59 & 2.47 & 2.39 & 2.32 & 2.27 & 2.22 \\
\textbf{27} & 4.21 & 3.35 & 2.96 & 2.73 & 2.57 & 2.46 & 2.37 & 2.31 & 2.25 & 2.20 \\
\textbf{28} & 4.20 & 3.34 & 2.95 & 2.71 & 2.56 & 2.45 & 2.36 & 2.29 & 2.24 & 2.19 \\
\textbf{29} & 4.18 & 3.33 & 2.93 & 2.70 & 2.55 & 2.43 & 2.35 & 2.28 & 2.22 & 2.18 \\
\textbf{30} & 4.17 & 3.32 & 2.92 & 2.69 & 2.53 & 2.42 & 2.33 & 2.27 & 2.21 & 2.16 \\
\textbf{35} & 4.12 & 3.27 & 2.87 & 2.64 & 2.49 & 2.37 & 2.29 & 2.22 & 2.16 & 2.11 \\
\textbf{40} & 4.08 & 3.23 & 2.84 & 2.61 & 2.45 & 2.34 & 2.25 & 2.18 & 2.12 & 2.08 \\
\textbf{50} & 4.03 & 3.18 & 2.79 & 2.56 & 2.40 & 2.29 & 2.20 & 2.13 & 2.07 & 2.03 \\
\textbf{60} & 4.00 & 3.15 & 2.76 & 2.53 & 2.37 & 2.25 & 2.17 & 2.10 & 2.04 & 1.99 \\
\textbf{70} & 3.98 & 3.13 & 2.74 & 2.50 & 2.35 & 2.23 & 2.14 & 2.07 & 2.02 & 1.97 \\
\textbf{80} & 3.96 & 3.11 & 2.72 & 2.49 & 2.33 & 2.21 & 2.13 & 2.06 & 2.00 & 1.95 \\
\textbf{90} & 3.95 & 3.10 & 2.71 & 2.47 & 2.32 & 2.20 & 2.11 & 2.04 & 1.99 & 1.94 \\
\textbf{100} & 3.94 & 3.09 & 2.70 & 2.46 & 2.31 & 2.19 & 2.10 & 2.03 & 1.97 & 1.93 \\
\textbf{120} & 3.92 & \textbf{3.07} & 2.68 & 2.45 & 2.29 & 2.18 & 2.09 & 2.02 & 1.96 & 1.91 \\\textbf{1000} & 3.85 & \textbf{3.00} & 2.61 & 2.38 & 2.22 & 2.11 & 2.02 & 1.95 & 1.89 & 1.84\end{array}$$
As seen from the table, the critical value of the F-test for the null hypothesis to be rejected is between 3.00 and 3.07. The actual F-statistic is 2217.95, which is far higher than the F-test critical value, and thus we reject the null hypothesis that all the slope coefficients are equal to 0.
Confidence interval (CI) is a closed interval in which the actual parameter is believed to lie with some degree of confidence. Confidence intervals are used to perform hypothesis tests. For instance, we may want to ascertain stock valuation using the capital asset pricing model (CAPM). In this case, we may wish to hypothesize that the beta possesses the market’s systematic risk or averaged beta.
The same analogy used in the regression analysis with one explanatory variable is also used in a multiple regression model using the t-test.
An economist tests the hypothesis that interest rates and inflation can explain GDP growth in a country. Using some 73 observations, the analyst formulates the following regression equation:
$$\text{GDP growth}=\hat{b} _0+\hat{b}_1 (\text{Interest})+\hat{b}_2 (\text{Inflation})$$
The regression estimates are as follows:
$$\begin{array}{l|c|c} & \textbf{Coefficient} & \textbf{Standard Error} \\\hline \text{Intercept} & 0.04 & 0.6\% \\ \text{Interest rates} & 0.25 & 6\% \\ \text{Inflation} & 0.20 & 4\% \end{array}$$
What is the 95% confidence interval for the coefficient on the inflation rate?
A. 0.12024 to 0.27976
B. 0.13024 to 0.37976
C. 0.12324 to 0.23976
D. 0.11324 to 0.13976
Solution
The correct answer is A
From the regression analysis, \(\hat{β}\) =0.20 and the estimated standard error, \(s_\hat{β}\) =0.04. The number of degrees of freedom is 73-3=70. So, the t-critical value at the 0.05 significance level is =\(t_{\frac{0.05}{2} , 73-2-1}=t_{0.025,70}=1.994\). Therefore, the 95% confidence level for the stock return is:
$$\hat{β}±t_c s_{\hat{β}}=0.2±1.994×0.04= [0.12024, 0.27976]$$
style=”max-width: 100%Practice Questions
Question 1
An analyst runs a regression of monthly value-stock returns on four independent variables over 48 months. The total sum of squares for the regression is 360 and the sum of squared errors is 120. Calculate the R2.
A. 42.1%
B. 50%
C. 33.3%
D. 66.7%
The correct answer is D.
$$ { R }^{ 2 }=\frac { ESS }{ TSS } =\frac { 360 – 120 }{ 360 } = 66.7%$$
Question 2
Refer to the previous problem and calculate the adjusted R2.
A. 27.1%
B. 63.6%
C. 72.9%
D. 36.4%
The correct answer is B.
$$ \begin{align*} \bar { R } ^{ 2 }&=1-\frac { n-1 }{ n-k-1 } \times (1 – { R }^{ 2 } )\\&=1-\frac { 48-1 }{ 48-4-1 } \times (1 – 0.667 )\\&= 63.6\% \end{align*}$$
Question 3
Refer to the previous problem. The analyst now adds four more independent variables to the regression and the new R2 increases to 69%. What is the new adjusted R2 and which model would the analyst prefer?
A. The analyst would prefer the model with four variables because its adjusted R2 is higher.
B. The analyst would prefer the model with four variables because its adjusted R2 is lower.
C. The analyst would prefer the model with eight variables because its adjusted R2 is higher.
D. The analyst would prefer the model with eight variables because its adjusted R2 is lower.
The correct answer is A.
$$ { \text{ New R } }^{ 2 }=69 \% $$
$$ { \text{ New adjusted R } }^{ 2 }=1-\frac { 48-1 }{ 48-8-1 } \times (1 – 0.69 ) = 62.6 \% $$
The analyst would prefer the first model because it has a higher adjusted R2 and the model has four independent variables as opposed to eight.
Question 4
An economist tests the hypothesis that GDP growth in a certain country can be explained by interest rates and inflation.
Using some 30 observations, the analyst formulates the following regression equation:
$$ \text{GDP growth} = { \hat { \beta } }_{ 0 } + { \hat { \beta } }_{ 1 } \text{Interest}+ { \hat { \beta } }_{ 2 } \text{Inflation} $$
Regression estimates are as follows:
$$\begin{array}{l|c|c} & \textbf{Coefficient} & \textbf{Standard Error} \\ \hline \text{Intercept} & 0.10 & 0.5\% \\ \text{Interest Rates} & 0.20 &0.05 \\ \text{Inflation} &0.15 &0.03 \end{array}$$
Is the coefficient for interest rates significant at 5%?
A. Since the test statistic < t-critical, we accept H0; the interest rate coefficient is not significant at the 5% level.
B. Since the test statistic > t-critical, we reject H0; the interest rate coefficient is not significant at the 5% level.
C. Since the test statistic > t-critical, we reject H0; the interest rate coefficient is significant at the 5% level.
D. Since the test statistic < t-critical, we accept H1; the interest rate coefficient is significant at the 5% level.
The correct answer is C.
We have GDP growth = 0.10 + 0.20(Int) + 0.15(Inf)
Hypothesis:
$$ { H }_{ 0 }:{ \hat { \beta } }_{ 1 } = 0 \quad vs \quad { H }_{ 1 }:{ \hat { \beta } }_{ 1 }≠0 $$
The test statistic is:
$$ t = \left( \frac { 0.20 – 0 }{ 0.05 } \right) = 4 $$
The critical value is t(α/2, n-k-1) = t0.025,27 = 2.052 (which can be found on the t-table).
$$\begin{array}{l|cccccc} \textbf{df/p} & \textbf{0.40} & \textbf{0.25} & \textbf{0.10} & \textbf{0.05} & \textbf{0.025} & \textbf{0.01} \\ \hline\textbf{25} & 0.256060 & 0.684430 & 1.316345 & 1.708141 & 2.05954 & 2.48511 \\ \textbf{26} & 0.255955 & 0.684043 & 1.314972 & 1.705618 & 2.05553 & 2.47863 \\ \textbf{27} & 0.255858 & 0.683685 & 1.313703 & 1.703288 & \bf{\textit{2.05183}} & 2.47266 \\ \textbf{28} & 0.255768 & 0.683353 & 1.312527 & 1.701131 & 2.04841 & 2.46714 \\ \textbf{29} & 0.255684 & 0.683044 & 1.311434 & 1.699127 & 2.04523 & 2.46202 \end{array}$$Decision: Since test statistic > t-critical, we reject H0.
Conclusion: The interest rate coefficient is significant at the 5% level.
Offered by AnalystPrep





Get Ahead on Your Study Prep This Cyber Monday! Save 35% on all CFA® and FRM® Unlimited Packages. Use code CYBERMONDAY at checkout. Offer ends Dec 1st.